 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort Range Correlation Transformer for Occluded Person Re-Identification
Jan 04, 2022
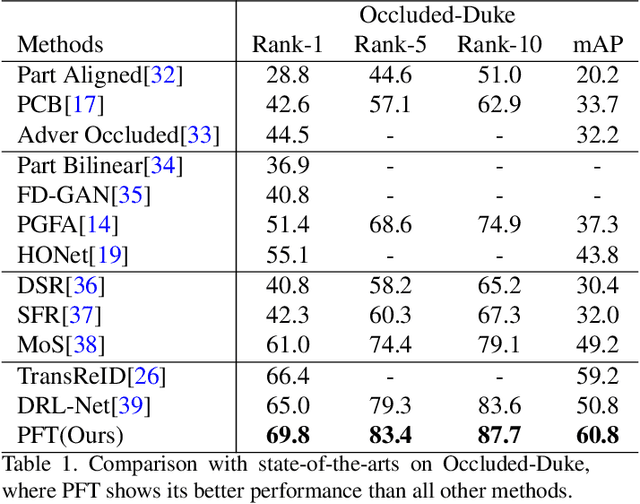


Occluded person re-identification is one of the challenging areas of computer vision, which faces problems such as inefficient feature representation and low recognition accuracy. Convolutional neural network pays more attention to the extraction of local features, therefore it is difficult to extract features of occluded pedestrians and the effect is not so satisfied. Recently, vision transformer is introduced into the field of re-identification and achieves the most advanced results by constructing the relationship of global features between patch sequences. However, the performance of vision transformer in extracting local features is inferior to that of convolutional neural network. Therefore, we design a partial feature transformer-based person re-identification framework named PFT. The proposed PFT utilizes three modules to enhance the efficiency of vision transformer. (1) Patch full dimension enhancement module. We design a learnable tensor with the same size as patch sequences, which is full-dimensional and deeply embedded in patch sequences to enrich the diversity of training samples. (2) Fusion and reconstruction module. We extract the less important part of obtained patch sequences, and fuse them with original patch sequence to reconstruct the original patch sequences. (3) Spatial Slicing Module. We slice and group patch sequences from spatial direction, which can effectively improve the short-range correlation of patch sequences. Experimental results over occluded and holistic re-identification datasets demonstrate that the proposed PFT network achieves superior performance consistently and outperforms the state-of-the-art methods.