 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow UMass-FSD Inadvertently Leverages Temporal Bias
Aug 02, 2022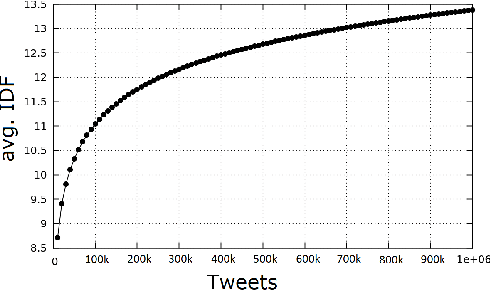
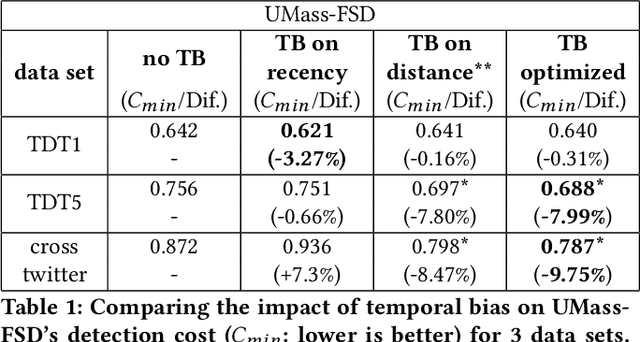
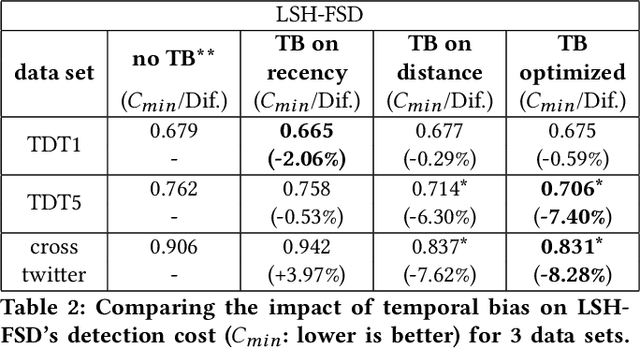
First Story Detection describes the task of identifying new events in a stream of documents. The UMass-FSD system is known for its strong performance in First Story Detection competitions. Recently, it has been frequently used as a high accuracy baseline in research publications. We are the first to discover that UMass-FSD inadvertently leverages temporal bias. Interestingly, the discovered bias contrasts previously known biases and performs significantly better. Our analysis reveals an increased contribution of temporally distant documents, resulting from an unusual way of handling incremental term statistics. We show that this form of temporal bias is also applicable to other well-known First Story Detection systems, where it improves the detection accuracy. To provide a more generalizable conclusion and demonstrate that the observed bias is not only an artefact of a particular implementation, we present a model that intentionally leverages a bias on temporal distance. Our model significantly improves the detection effectiveness of state-of-the-art First Story Detection systems.
* Temporal Bias, First Story Detection, Topic Detection and Tracking, UMass-FSD, LSH-FSD
Parameterizing Kterm Hashing
Aug 02, 2022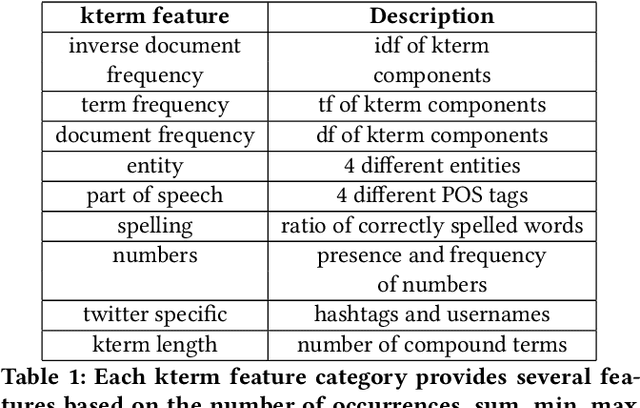
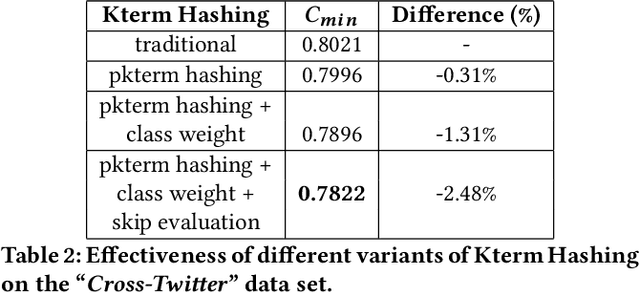
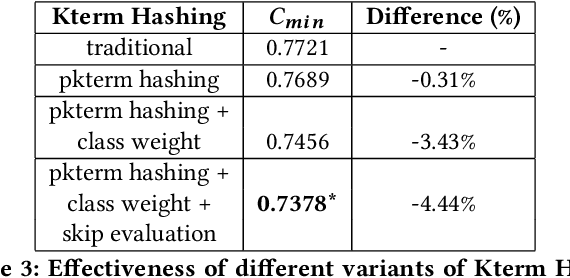

Kterm Hashing provides an innovative approach to novelty detection on massive data streams. Previous research focused on maximizing the efficiency of Kterm Hashing and succeeded in scaling First Story Detection to Twitter-size data stream without sacrificing detection accuracy. In this paper, we focus on improving the effectiveness of Kterm Hashing. Traditionally, all kterms are considered as equally important when calculating a document's degree of novelty with respect to the past. We believe that certain kterms are more important than others and hypothesize that uniform kterm weights are sub-optimal for determining novelty in data streams. To validate our hypothesis, we parameterize Kterm Hashing by assigning weights to kterms based on their characteristics. Our experiments apply Kterm Hashing in a First Story Detection setting and reveal that parameterized Kterm Hashing can surpass state-of-the-art detection accuracy and significantly outperform the uniformly weighted approach.
* Kterm Hashing, Novelty Detection, First Story Detection
Spotting Rumors via Novelty Detection
Nov 19, 2016
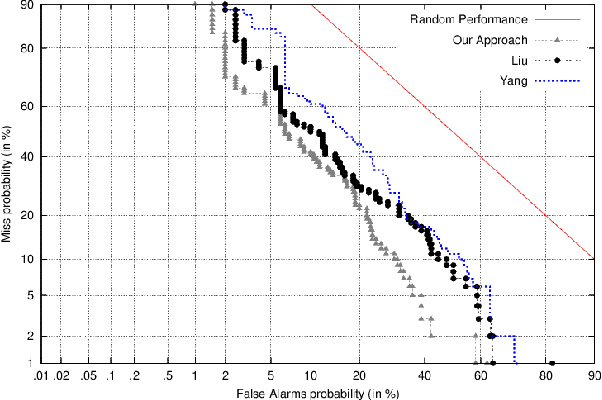

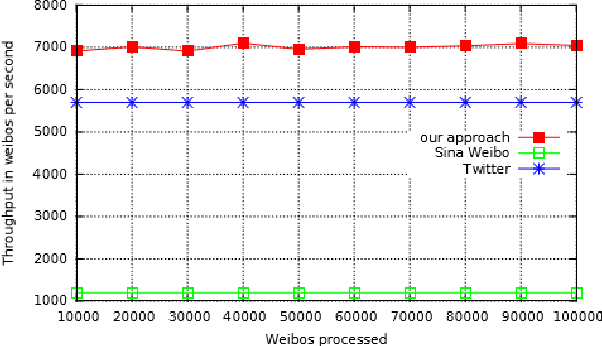
Rumour detection is hard because the most accurate systems operate retrospectively, only recognizing rumours once they have collected repeated signals. By then the rumours might have already spread and caused harm. We introduce a new category of features based on novelty, tailored to detect rumours early on. To compensate for the absence of repeated signals, we make use of news wire as an additional data source. Unconfirmed (novel) information with respect to the news articles is considered as an indication of rumours. Additionally we introduce pseudo feedback, which assumes that documents that are similar to previous rumours, are more likely to also be a rumour. Comparison with other real-time approaches shows that novelty based features in conjunction with pseudo feedback perform significantly better, when detecting rumours instantly after their publication.