 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameterizing Kterm Hashing
Paper and Code
Aug 02, 2022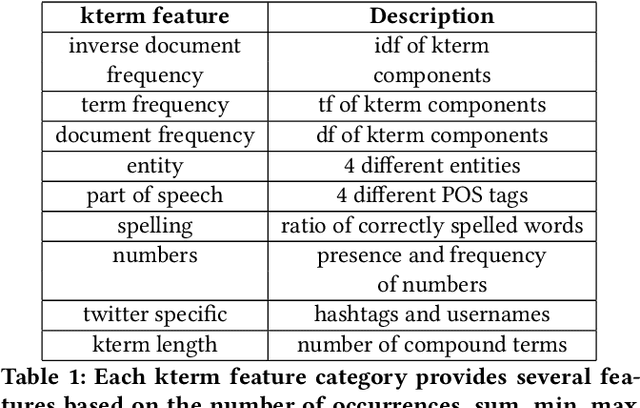
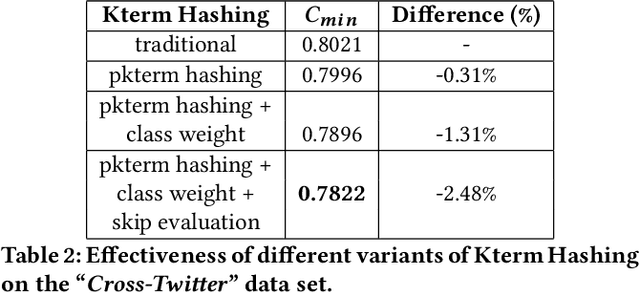
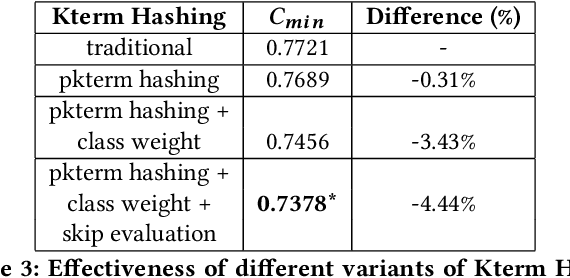

Kterm Hashing provides an innovative approach to novelty detection on massive data streams. Previous research focused on maximizing the efficiency of Kterm Hashing and succeeded in scaling First Story Detection to Twitter-size data stream without sacrificing detection accuracy. In this paper, we focus on improving the effectiveness of Kterm Hashing. Traditionally, all kterms are considered as equally important when calculating a document's degree of novelty with respect to the past. We believe that certain kterms are more important than others and hypothesize that uniform kterm weights are sub-optimal for determining novelty in data streams. To validate our hypothesis, we parameterize Kterm Hashing by assigning weights to kterms based on their characteristics. Our experiments apply Kterm Hashing in a First Story Detection setting and reveal that parameterized Kterm Hashing can surpass state-of-the-art detection accuracy and significantly outperform the uniformly weighted approach.