 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Shortcut to Induction Head: How Data Diversity Shapes Algorithm Selection in Transformers
Dec 21, 2025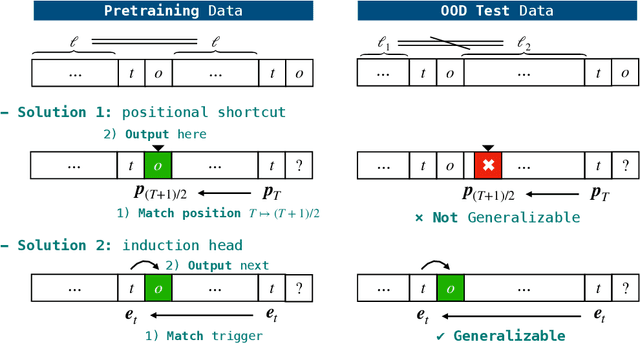
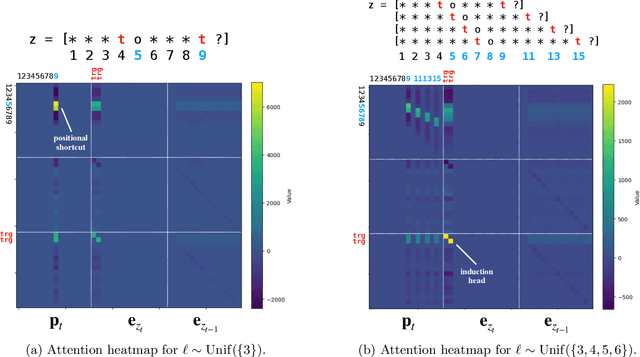
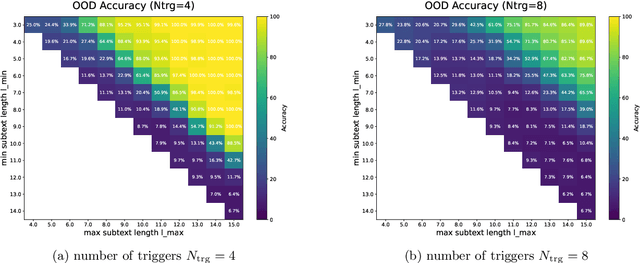
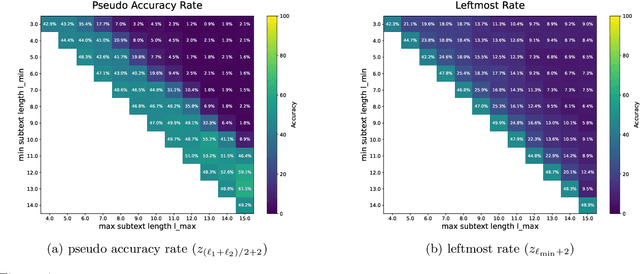
Transformers can implement both generalizable algorithms (e.g., induction heads) and simple positional shortcuts (e.g., memorizing fixed output positions). In this work, we study how the choice of pretraining data distribution steers a shallow transformer toward one behavior or the other. Focusing on a minimal trigger-output prediction task -- copying the token immediately following a special trigger upon its second occurrence -- we present a rigorous analysis of gradient-based training of a single-layer transformer. In both the infinite and finite sample regimes, we prove a transition in the learned mechanism: if input sequences exhibit sufficient diversity, measured by a low ``max-sum'' ratio of trigger-to-trigger distances, the trained model implements an induction head and generalizes to unseen contexts; by contrast, when this ratio is large, the model resorts to a positional shortcut and fails to generalize out-of-distribution (OOD). We also reveal a trade-off between the pretraining context length and OOD generalization, and derive the optimal pretraining distribution that minimizes computational cost per sample. Finally, we validate our theoretical predictions with controlled synthetic experiments, demonstrating that broadening context distributions robustly induces induction heads and enables OOD generalization. Our results shed light on the algorithmic biases of pretrained transformers and offer conceptual guidelines for data-driven control of their learned behaviors.
Sample-efficient quantum error mitigation via classical learning surrogates
Nov 10, 2025The pursuit of practical quantum utility on near-term quantum processors is critically challenged by their inherent noise. Quantum error mitigation (QEM) techniques are leading solutions to improve computation fidelity with relatively low qubit-overhead, while full-scale quantum error correction remains a distant goal. However, QEM techniques incur substantial measurement overheads, especially when applied to families of quantum circuits parameterized by classical inputs. Focusing on zero-noise extrapolation (ZNE), a widely adopted QEM technique, here we devise the surrogate-enabled ZNE (S-ZNE), which leverages classical learning surrogates to perform ZNE entirely on the classical side. Unlike conventional ZNE, whose measurement cost scales linearly with the number of circuits, S-ZNE requires only constant measurement overhead for an entire family of quantum circuits, offering superior scalability. Theoretical analysis indicates that S-ZNE achieves accuracy comparable to conventional ZNE in many practical scenarios, and numerical experiments on up to 100-qubit ground-state energy and quantum metrology tasks confirm its effectiveness. Our approach provides a template that can be effectively extended to other quantum error mitigation protocols, opening a promising path toward scalable error mitigation.
Pretrained transformer efficiently learns low-dimensional target functions in-context
Nov 04, 2024


Transformers can efficiently learn in-context from example demonstrations. Most existing theoretical analyses studied the in-context learning (ICL) ability of transformers for linear function classes, where it is typically shown that the minimizer of the pretraining loss implements one gradient descent step on the least squares objective. However, this simplified linear setting arguably does not demonstrate the statistical efficiency of ICL, since the pretrained transformer does not outperform directly solving linear regression on the test prompt. In this paper, we study ICL of a nonlinear function class via transformer with nonlinear MLP layer: given a class of \textit{single-index} target functions $f_*(\boldsymbol{x}) = \sigma_*(\langle\boldsymbol{x},\boldsymbol{\beta}\rangle)$, where the index features $\boldsymbol{\beta}\in\mathbb{R}^d$ are drawn from a $r$-dimensional subspace, we show that a nonlinear transformer optimized by gradient descent (with a pretraining sample complexity that depends on the \textit{information exponent} of the link functions $\sigma_*$) learns $f_*$ in-context with a prompt length that only depends on the dimension of the distribution of target functions $r$; in contrast, any algorithm that directly learns $f_*$ on test prompt yields a statistical complexity that scales with the ambient dimension $d$. Our result highlights the adaptivity of the pretrained transformer to low-dimensional structures of the function class, which enables sample-efficient ICL that outperforms estimators that only have access to the in-context data.
Learning sum of diverse features: computational hardness and efficient gradient-based training for ridge combinations
Jun 17, 2024


We study the computational and sample complexity of learning a target function $f_*:\mathbb{R}^d\to\mathbb{R}$ with additive structure, that is, $f_*(x) = \frac{1}{\sqrt{M}}\sum_{m=1}^M f_m(\langle x, v_m\rangle)$, where $f_1,f_2,...,f_M:\mathbb{R}\to\mathbb{R}$ are nonlinear link functions of single-index models (ridge functions) with diverse and near-orthogonal index features $\{v_m\}_{m=1}^M$, and the number of additive tasks $M$ grows with the dimensionality $M\asymp d^\gamma$ for $\gamma\ge 0$. This problem setting is motivated by the classical additive model literature, the recent representation learning theory of two-layer neural network, and large-scale pretraining where the model simultaneously acquires a large number of "skills" that are often localized in distinct parts of the trained network. We prove that a large subset of polynomial $f_*$ can be efficiently learned by gradient descent training of a two-layer neural network, with a polynomial statistical and computational complexity that depends on the number of tasks $M$ and the information exponent of $f_m$, despite the unknown link function and $M$ growing with the dimensionality. We complement this learnability guarantee with computational hardness result by establishing statistical query (SQ) lower bounds for both the correlational SQ and full SQ algorithms.