 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative weather for improved crop model simulations
Mar 31, 2024



Accurate and precise crop yield prediction is invaluable for decision making at both farm levels and regional levels. To make yield prediction, crop models are widely used for their capability to simulate hypothetical scenarios. While accuracy and precision of yield prediction critically depend on weather inputs to simulations, surprisingly little attention has been paid to preparing weather inputs. We propose a new method to construct generative models for long-term weather forecasts and ultimately improve crop yield prediction. We demonstrate use of the method in two representative scenarios -- single-year production of wheat, barley and canola and three-year production using rotations of these crops. Results show significant improvement from the conventional method, measured in terms of mean and standard deviation of prediction errors. Our method outperformed the conventional method in every one of 18 metrics for the first scenario and in 29 out of 36 metrics for the second scenario. For individual crop modellers to start applying the method to their problems, technical details are carefully explained, and all the code, trained PyTorch models, APSIM simulation files and result data are made available.
Mixtures of Gaussian process experts based on kernel stick-breaking processes
May 05, 2023Mixtures of Gaussian process experts is a class of models that can simultaneously address two of the key limitations inherent in standard Gaussian processes: scalability and predictive performance. In particular, models that use Dirichlet processes as gating functions permit straightforward interpretation and automatic selection of the number of experts in a mixture. While the existing models are intuitive and capable of capturing non-stationarity, multi-modality and heteroskedasticity, the simplicity of their gating functions may limit the predictive performance when applied to complex data-generating processes. Capitalising on the recent advancement in the dependent Dirichlet processes literature, we propose a new mixture model of Gaussian process experts based on kernel stick-breaking processes. Our model maintains the intuitive appeal yet improve the performance of the existing models. To make it practical, we design a sampler for posterior computation based on the slice sampling. The model behaviour and improved predictive performance are demonstrated in experiments using six datasets.
Deep reinforcement learning for irrigation scheduling using high-dimensional sensor feedback
Jan 02, 2023



Deep reinforcement learning has considerable potential to improve irrigation scheduling in many cropping systems by applying adaptive amounts of water based on various measurements over time. The goal is to discover an intelligent decision rule that processes information available to growers and prescribes sensible irrigation amounts for the time steps considered. Due to the technical novelty, however, the research on the technique remains sparse and impractical. To accelerate the progress, the paper proposes a general framework and actionable procedure that allow researchers to formulate their own optimisation problems and implement solution algorithms based on deep reinforcement learning. The effectiveness of the framework was demonstrated using a case study of irrigated wheat grown in a productive region of Australia where profits were maximised. Specifically, the decision rule takes nine state variable inputs: crop phenological stage, leaf area index, extractable soil water for each of the five top layers, cumulative rainfall and cumulative irrigation. It returns a probabilistic prescription over five candidate irrigation amounts (0, 10, 20, 30 and 40 mm) every day. The production system was simulated at Goondiwindi using the APSIM-Wheat crop model. After training in the learning environment using 1981--2010 weather data, the learned decision rule was tested individually for each year of 2011--2020. The results were compared against the benchmark profits obtained using irrigation schedules optimised individually for each of the considered years. The discovered decision rule prescribed daily irrigation amounts that achieved more than 96% of the benchmark profits. The framework is general and applicable to a wide range of cropping systems with realistic optimisation problems.
The case for fully Bayesian optimisation in small-sample trials
Aug 30, 2022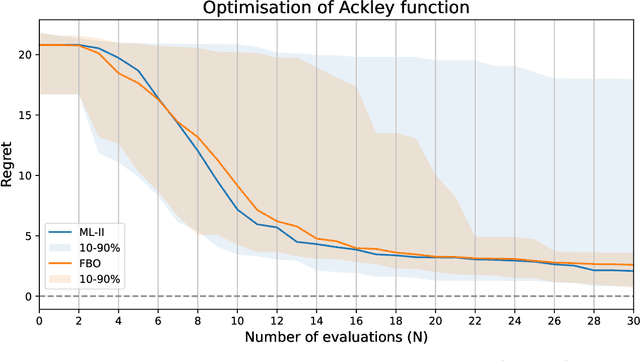


While sample efficiency is the main motive for use of Bayesian optimisation when black-box functions are expensive to evaluate, the standard approach based on type II maximum likelihood (ML-II) may fail and result in disappointing performance in small-sample trials. The paper provides three compelling reasons to adopt fully Bayesian optimisation (FBO) as an alternative. First, failures of ML-II are more commonplace than implied by the existing studies using the contrived settings. Second, FBO is more robust than ML-II, and the price of robustness is almost trivial. Third, FBO has become simple to implement and fast enough to be practical. The paper supports the argument using relevant experiments, which reflect the current practice regarding models, algorithms, and software platforms. Since the benefits seem to outweigh the costs, researchers should consider adopting FBO for their applications so that they can guard against potential failures that end up wasting precious research resources.