 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Enhancement of the Generalization and Robustness of Language Models via Bi-Stage Optimization
Mar 19, 2025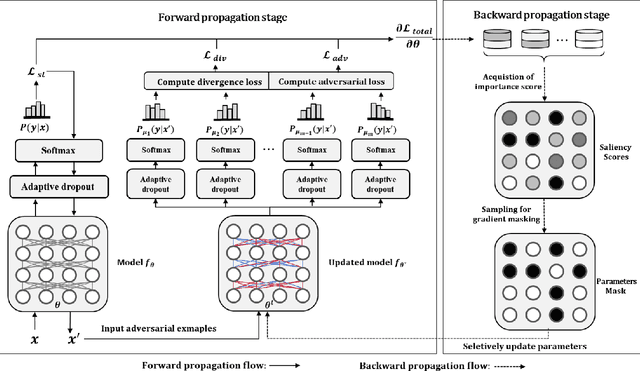
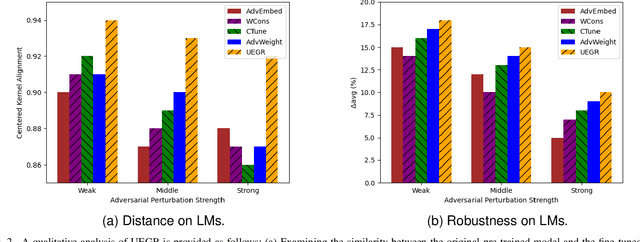
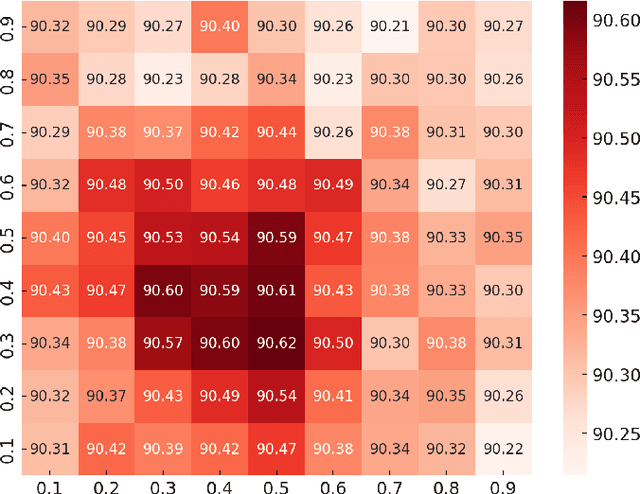
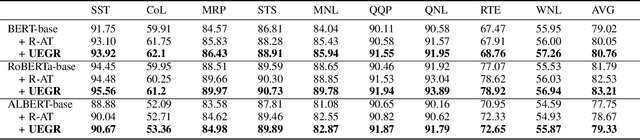
Neural network language models (LMs) are confronted with significant challenges in generalization and robustness. Currently, many studies focus on improving either generalization or robustness in isolation, without methods addressing both aspects simultaneously, which presents a significant challenge in developing LMs that are both robust and generalized. In this paper, we propose a bi-stage optimization framework to uniformly enhance both the generalization and robustness of LMs, termed UEGR. Specifically, during the forward propagation stage, we enrich the output probability distributions of adversarial samples by adaptive dropout to generate diverse sub models, and incorporate JS divergence and adversarial losses of these output distributions to reinforce output stability. During backward propagation stage, we compute parameter saliency scores and selectively update only the most critical parameters to minimize unnecessary deviations and consolidate the model's resilience. Theoretical analysis shows that our framework includes gradient regularization to limit the model's sensitivity to input perturbations and selective parameter updates to flatten the loss landscape, thus improving both generalization and robustness. The experimental results show that our method significantly improves the generalization and robustness of LMs compared to other existing methods across 13 publicly available language datasets, achieving state-of-the-art (SOTA) performance.