 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Labyrinth of Links: Navigating the Associative Maze of Multi-modal LLMs
Oct 02, 2024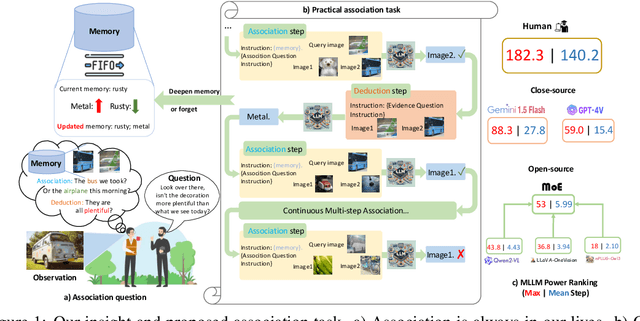
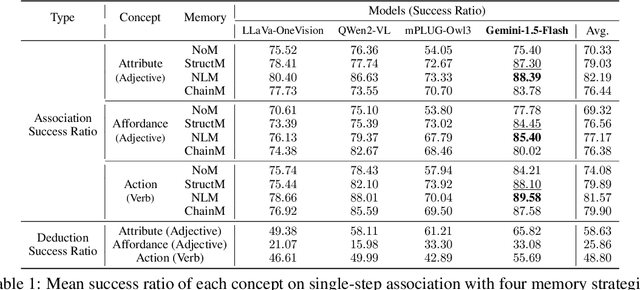
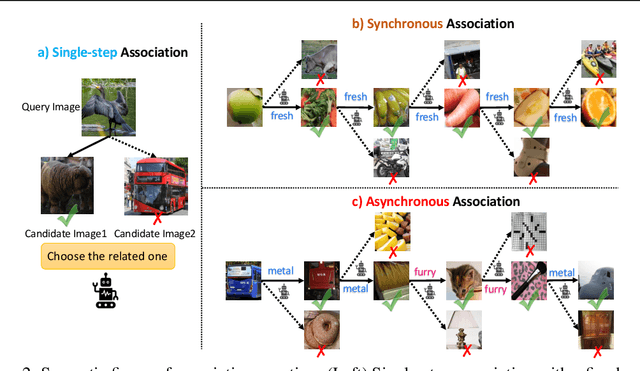

Multi-modal Large Language Models (MLLMs) have exhibited impressive capability. However, recently many deficiencies of MLLMs have been found compared to human intelligence, $\textit{e.g.}$, hallucination. To drive the MLLMs study, the community dedicated efforts to building larger benchmarks with complex tasks. In this paper, we propose benchmarking an essential but usually overlooked intelligence: $\textbf{association}$, a human's basic capability to link observation and prior practice memory. To comprehensively investigate MLLM's performance on the association, we formulate the association task and devise a standard benchmark based on adjective and verb semantic concepts. Instead of costly data annotation and curation, we propose a convenient $\textbf{annotation-free}$ construction method transforming the general dataset for our association tasks. Simultaneously, we devise a rigorous data refinement process to eliminate confusion in the raw dataset. Building on this database, we establish three levels of association tasks: single-step, synchronous, and asynchronous associations. Moreover, we conduct a comprehensive investigation into the MLLMs' zero-shot association capabilities, addressing multiple dimensions, including three distinct memory strategies, both open-source and closed-source MLLMs, cutting-edge Mixture-of-Experts (MoE) models, and the involvement of human experts. Our systematic investigation shows that current open-source MLLMs consistently exhibit poor capability in our association tasks, even the currently state-of-the-art GPT-4V(vision) also has a significant gap compared to humans. We believe our benchmark would pave the way for future MLLM studies. $\textit{Our data and code are available at:}$ https://mvig-rhos.com/llm_inception.
Event prediction and causality inference despite incomplete information
Jun 09, 2024



We explored the challenge of predicting and explaining the occurrence of events within sequences of data points. Our focus was particularly on scenarios in which unknown triggers causing the occurrence of events may consist of non-consecutive, masked, noisy data points. This scenario is akin to an agent tasked with learning to predict and explain the occurrence of events without understanding the underlying processes or having access to crucial information. Such scenarios are encountered across various fields, such as genomics, hardware and software verification, and financial time series prediction. We combined analytical, simulation, and machine learning (ML) approaches to investigate, quantify, and provide solutions to this challenge. We deduced and validated equations generally applicable to any variation of the underlying challenge. Using these equations, we (1) described how the level of complexity changes with various parameters (e.g., number of apparent and hidden states, trigger length, confidence, etc.) and (2) quantified the data needed to successfully train an ML model. We then (3) proved our ML solution learns and subsequently identifies unknown triggers and predicts the occurrence of events. If the complexity of the challenge is too high, our ML solution can identify trigger candidates to be used to interactively probe the system under investigation to determine the true trigger in a way considerably more efficient than brute force methods. By sharing our findings, we aim to assist others grappling with similar challenges, enabling estimates on the complexity of their problem, the data required and a solution to solve it.