Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Automatic Text Extractive Summarization Based on Graph and pre-trained Language Model Attention
Oct 10, 2021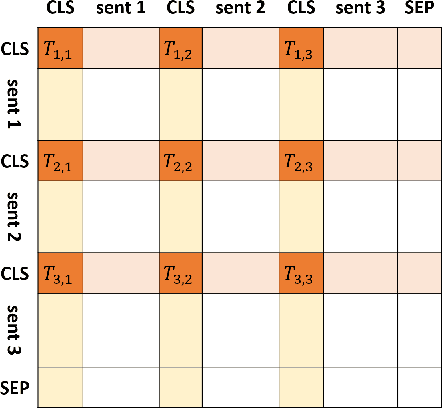
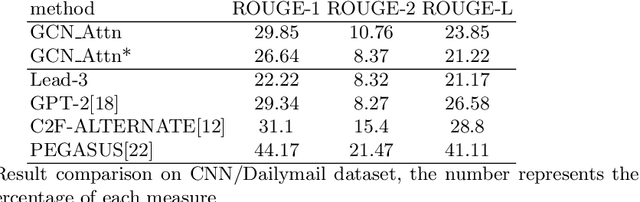
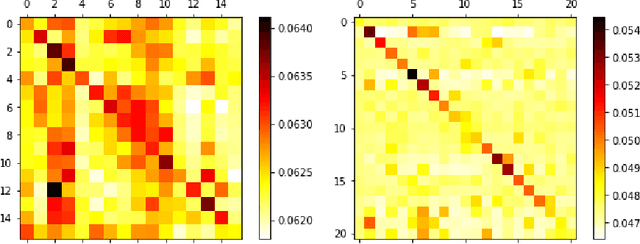
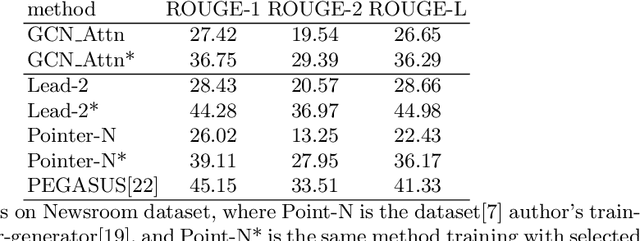
Representing text as graph to solve the summarization task has been discussed for more than 10 years. However, with the development of attention or Transformer, the connection between attention and graph remains poorly understood. We demonstrate that the text structure can be analyzed through the attention matrix, which represents the relation between sentences by the attention weights. In this work, we show that the attention matrix produced in pre-training language model can be used as the adjacent matrix of graph convolutional network model. Our model performs a competitive result on 2 different datasets based on the ROUGE index. Also, with fewer parameters, the model reduces the computation resource when training and inferring.
Via