 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRATs-NAS: Redirection of Adjacent Trails on GCN for Neural Architecture Search
May 09, 2023Various hand-designed CNN architectures have been developed, such as VGG, ResNet, DenseNet, etc., and achieve State-of-the-Art (SoTA) levels on different tasks. Neural Architecture Search (NAS) now focuses on automatically finding the best CNN architecture to handle the above tasks. However, the verification of a searched architecture is very time-consuming and makes predictor-based methods become an essential and important branch of NAS. Two commonly used techniques to build predictors are graph-convolution networks (GCN) and multilayer perceptron (MLP). In this paper, we consider the difference between GCN and MLP on adjacent operation trails and then propose the Redirected Adjacent Trails NAS (RATs-NAS) to quickly search for the desired neural network architecture. The RATs-NAS consists of two components: the Redirected Adjacent Trails GCN (RATs-GCN) and the Predictor-based Search Space Sampling (P3S) module. RATs-GCN can change trails and their strengths to search for a better neural network architecture. P3S can rapidly focus on tighter intervals of FLOPs in the search space. Based on our observations on cell-based NAS, we believe that architectures with similar FLOPs will perform similarly. Finally, the RATs-NAS consisting of RATs-GCN and P3S beats WeakNAS, Arch-Graph, and others by a significant margin on three sub-datasets of NASBench-201.
Siamese-NAS: Using Trained Samples Efficiently to Find Lightweight Neural Architecture by Prior Knowledge
Oct 02, 2022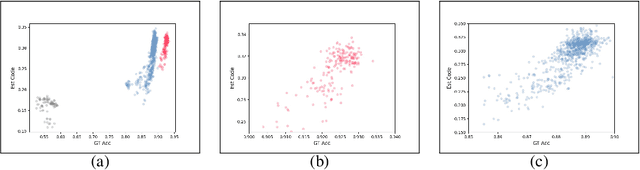
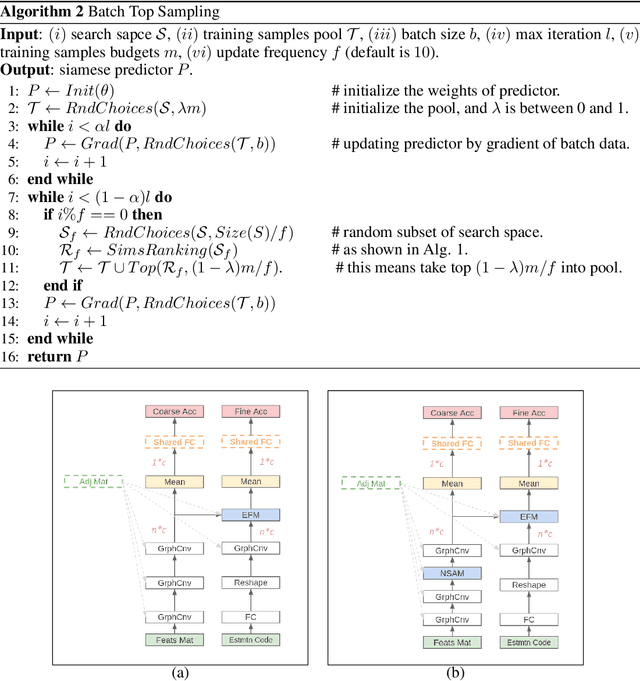
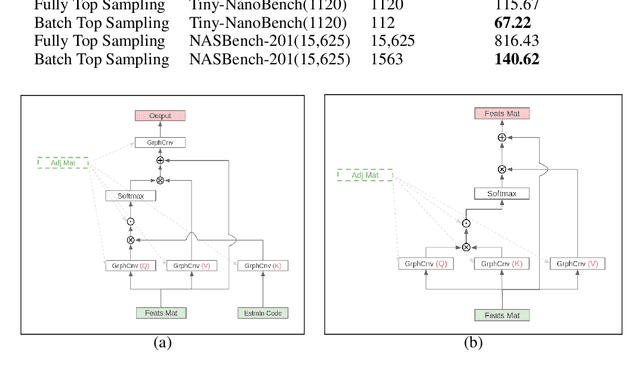
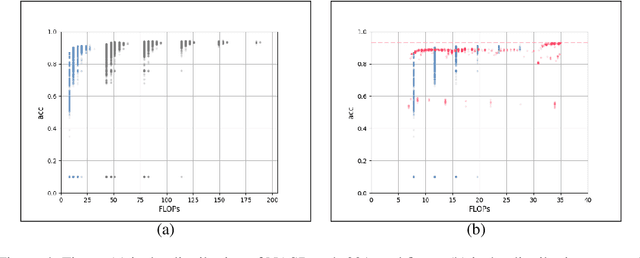
In the past decade, many architectures of convolution neural networks were designed by handcraft, such as Vgg16, ResNet, DenseNet, etc. They all achieve state-of-the-art level on different tasks in their time. However, it still relies on human intuition and experience, and it also takes so much time consumption for trial and error. Neural Architecture Search (NAS) focused on this issue. In recent works, the Neural Predictor has significantly improved with few training architectures as training samples. However, the sampling efficiency is already considerable. In this paper, our proposed Siamese-Predictor is inspired by past works of predictor-based NAS. It is constructed with the proposed Estimation Code, which is the prior knowledge about the training procedure. The proposed Siamese-Predictor gets significant benefits from this idea. This idea causes it to surpass the current SOTA predictor on NASBench-201. In order to explore the impact of the Estimation Code, we analyze the relationship between it and accuracy. We also propose the search space Tiny-NanoBench for lightweight CNN architecture. This well-designed search space is easier to find better architecture with few FLOPs than NASBench-201. In summary, the proposed Siamese-Predictor is a predictor-based NAS. It achieves the SOTA level, especially with limited computation budgets. It applied to the proposed Tiny-NanoBench can just use a few trained samples to find extremely lightweight CNN architecture.
SFPN: Synthetic FPN for Object Detection
Mar 04, 2022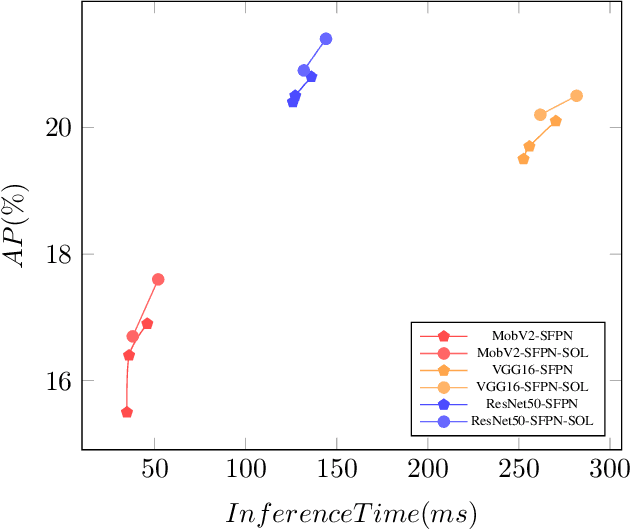
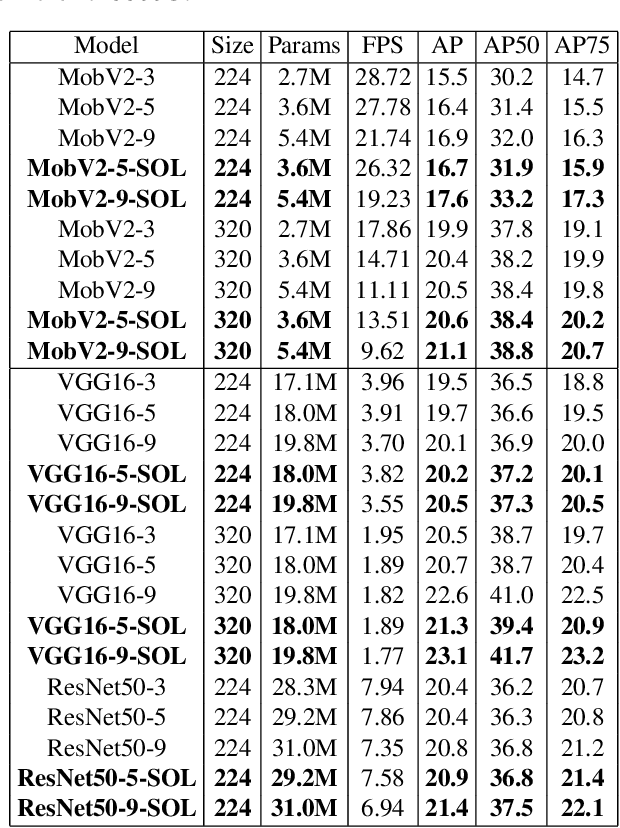

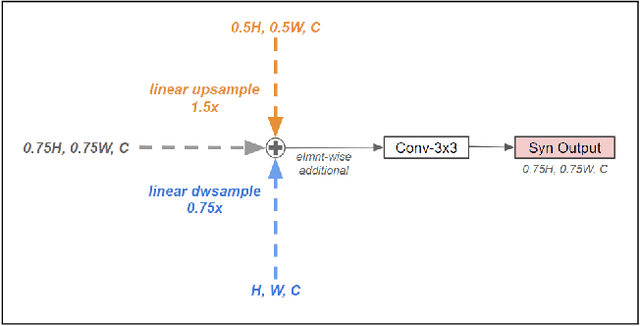
FPN (Feature Pyramid Network) has become a basic component of most SoTA one stage object detectors. Many previous studies have repeatedly proved that FPN can caputre better multi-scale feature maps to more precisely describe objects if they are with different sizes. However, for most backbones such VGG, ResNet, or DenseNet, the feature maps at each layer are downsized to their quarters due to the pooling operation or convolutions with stride 2. The gap of down-scaling-by-2 is large and makes its FPN not fuse the features smoothly. This paper proposes a new SFPN (Synthetic Fusion Pyramid Network) arichtecture which creates various synthetic layers between layers of the original FPN to enhance the accuracy of light-weight CNN backones to extract objects' visual features more accurately. Finally, experiments prove the SFPN architecture outperforms either the large backbone VGG16, ResNet50 or light-weight backbones such as MobilenetV2 based on AP score.
CSL-YOLO: A New Lightweight Object Detection System for Edge Computing
Jul 10, 2021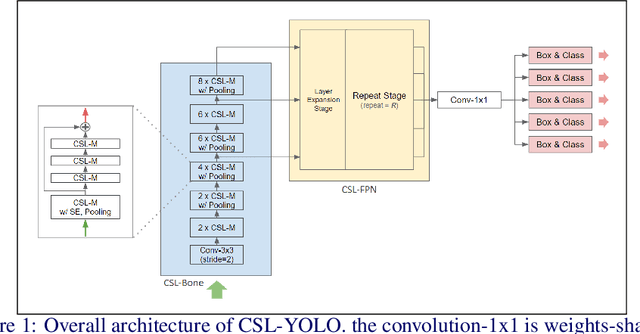
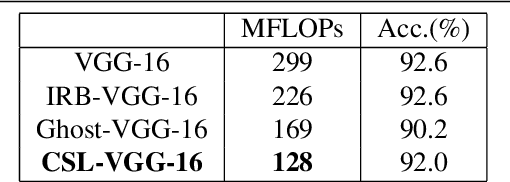
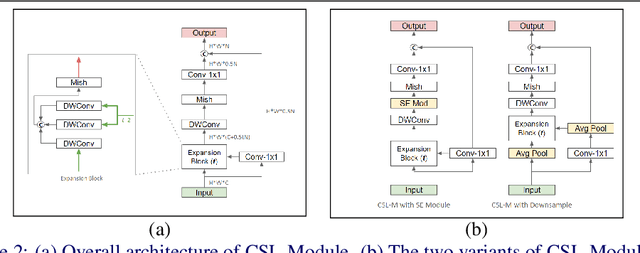
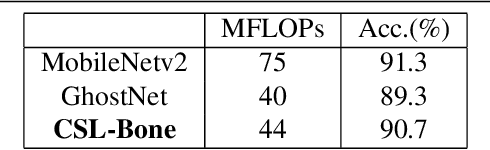
The development of lightweight object detectors is essential due to the limited computation resources. To reduce the computation cost, how to generate redundant features plays a significant role. This paper proposes a new lightweight Convolution method Cross-Stage Lightweight (CSL) Module, to generate redundant features from cheap operations. In the intermediate expansion stage, we replaced Pointwise Convolution with Depthwise Convolution to produce candidate features. The proposed CSL-Module can reduce the computation cost significantly. Experiments conducted at MS-COCO show that the proposed CSL-Module can approximate the fitting ability of Convolution-3x3. Finally, we use the module to construct a lightweight detector CSL-YOLO, achieving better detection performance with only 43% FLOPs and 52% parameters than Tiny-YOLOv4.