 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOI-Bench: An Option Injection Benchmark for Evaluating LLM Susceptibility to Directive Interference
Jan 19, 2026Benchmarking large language models (LLMs) is critical for understanding their capabilities, limitations, and robustness. In addition to interface artifacts, prior studies have shown that LLM decisions can be influenced by directive signals such as social cues, framing, and instructions. In this work, we introduce option injection, a benchmarking approach that augments the multiple-choice question answering (MCQA) interface with an additional option containing a misleading directive, leveraging standardized choice structure and scalable evaluation. We construct OI-Bench, a benchmark of 3,000 questions spanning knowledge, reasoning, and commonsense tasks, with 16 directive types covering social compliance, bonus framing, threat framing, and instructional interference. This setting combines manipulation of the choice interface with directive-based interference, enabling systematic assessment of model susceptibility. We evaluate 12 LLMs to analyze attack success rates, behavioral responses, and further investigate mitigation strategies ranging from inference-time prompting to post-training alignment. Experimental results reveal substantial vulnerabilities and heterogeneous robustness across models. OI-Bench is expected to support more systematic evaluation of LLM robustness to directive interference within choice-based interfaces.
Stay Hungry, Stay Foolish: On the Extended Reading Articles Generation with LLMs
Apr 21, 2025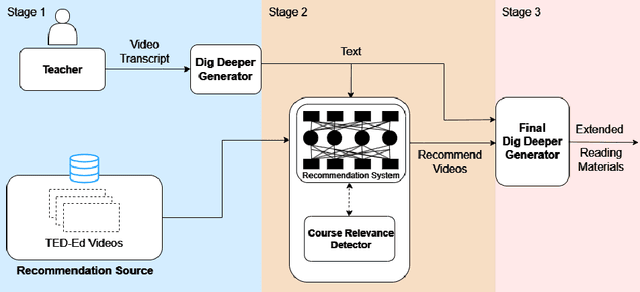


The process of creating educational materials is both time-consuming and demanding for educators. This research explores the potential of Large Language Models (LLMs) to streamline this task by automating the generation of extended reading materials and relevant course suggestions. Using the TED-Ed Dig Deeper sections as an initial exploration, we investigate how supplementary articles can be enriched with contextual knowledge and connected to additional learning resources. Our method begins by generating extended articles from video transcripts, leveraging LLMs to include historical insights, cultural examples, and illustrative anecdotes. A recommendation system employing semantic similarity ranking identifies related courses, followed by an LLM-based refinement process to enhance relevance. The final articles are tailored to seamlessly integrate these recommendations, ensuring they remain cohesive and informative. Experimental evaluations demonstrate that our model produces high-quality content and accurate course suggestions, assessed through metrics such as Hit Rate, semantic similarity, and coherence. Our experimental analysis highlight the nuanced differences between the generated and existing materials, underscoring the model's capacity to offer more engaging and accessible learning experiences. This study showcases how LLMs can bridge the gap between core content and supplementary learning, providing students with additional recommended resources while also assisting teachers in designing educational materials.