 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Graph Generation for Query Navigation: Use of Frequency Classes for Topic Extraction
Dec 12, 1997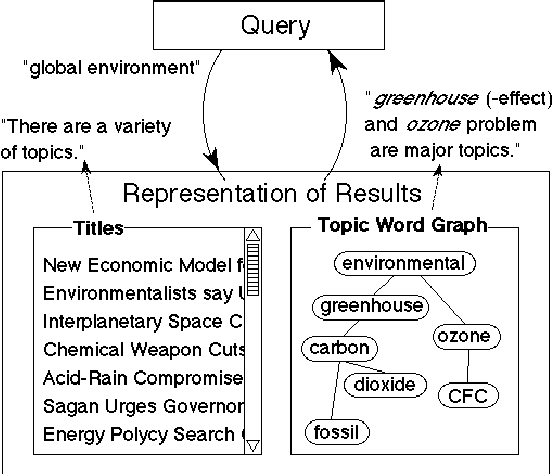
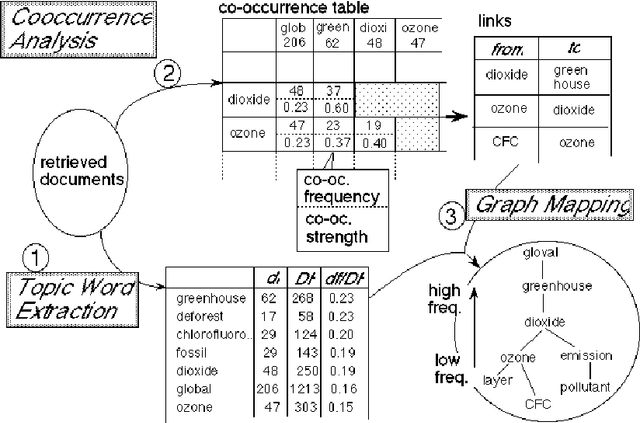
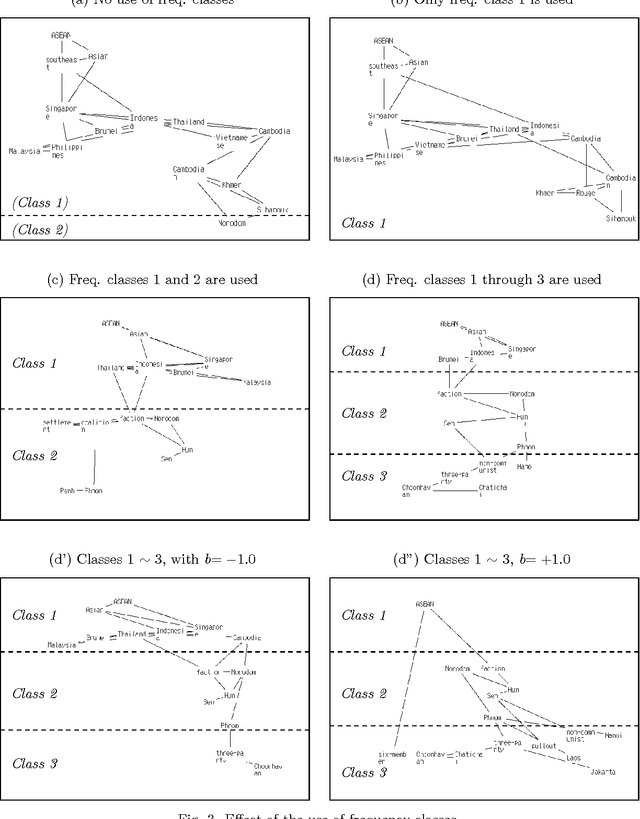
To make an interactive guidance mechanism for document retrieval systems, we developed a user-interface which presents users the visualized map of topics at each stage of retrieval process. Topic words are automatically extracted by frequency analysis and the strength of the relationships between topic words is measured by their co-occurrence. A major factor affecting a user's impression of a given topic word graph is the balance between common topic words and specific topic words. By using frequency classes for topic word extraction, we made it possible to select well-balanced set of topic words, and to adjust the balance of common and specific topic words.
* 6 pages, 3 figures
Co-occurrence Vectors from Corpora vs. Distance Vectors from Dictionaries
Apr 01, 1995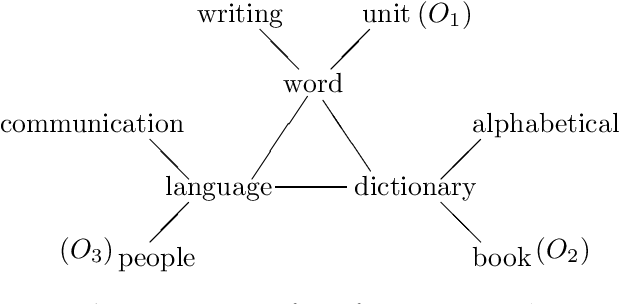



A comparison was made of vectors derived by using ordinary co-occurrence statistics from large text corpora and of vectors derived by measuring the inter-word distances in dictionary definitions. The precision of word sense disambiguation by using co-occurrence vectors from the 1987 Wall Street Journal (20M total words) was higher than that by using distance vectors from the Collins English Dictionary (60K head words + 1.6M definition words). However, other experimental results suggest that distance vectors contain some different semantic information from co-occurrence vectors.
* 6 pages, appeared in the Proc. of COLING94 (pp. 304-309).