 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Geometry of Nonlinear Embeddings in Kernel Discriminant Analysis
May 12, 2020
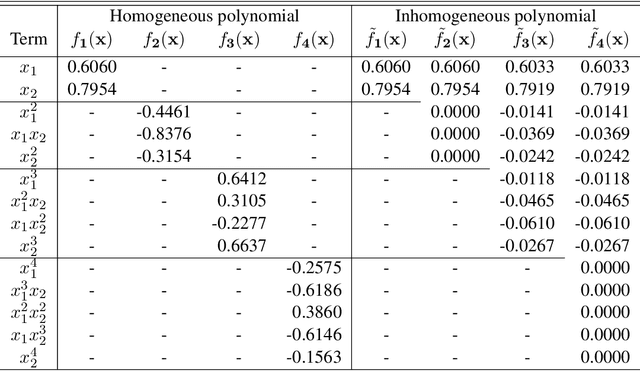

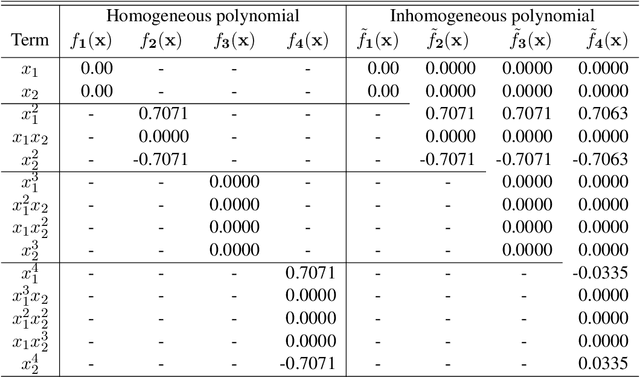
Fisher's linear discriminant analysis is a classical method for classification, yet it is limited to capturing linear features only. Kernel discriminant analysis as an extension is known to successfully alleviate the limitation through a nonlinear feature mapping. We study the geometry of nonlinear embeddings in discriminant analysis with polynomial kernels and Gaussian kernel by identifying the population-level discriminant function that depends on the data distribution and the kernel. In order to obtain the discriminant function, we solve a generalized eigenvalue problem with between-class and within-class covariance operators. The polynomial discriminants are shown to capture the class difference through the population moments explicitly. For approximation of the Gaussian discriminant, we use a particular representation of the Gaussian kernel by utilizing the exponential generating function for Hermite polynomials. We also show that the Gaussian discriminant can be approximated using randomized projections of the data. Our results illuminate how the data distribution and the kernel interact in determination of the nonlinear embedding for discrimination, and provide a guideline for choice of the kernel and its parameters.
Dimensionality Reduction for Binary Data through the Projection of Natural Parameters
Oct 21, 2015



Principal component analysis (PCA) for binary data, known as logistic PCA, has become a popular alternative to dimensionality reduction of binary data. It is motivated as an extension of ordinary PCA by means of a matrix factorization, akin to the singular value decomposition, that maximizes the Bernoulli log-likelihood. We propose a new formulation of logistic PCA which extends Pearson's formulation of a low dimensional data representation with minimum error to binary data. Our formulation does not require a matrix factorization, as previous methods do, but instead looks for projections of the natural parameters from the saturated model. Due to this difference, the number of parameters does not grow with the number of observations and the principal component scores on new data can be computed with simple matrix multiplication. We derive explicit solutions for data matrices of special structure and provide computationally efficient algorithms for solving for the principal component loadings. Through simulation experiments and an analysis of medical diagnoses data, we compare our formulation of logistic PCA to the previous formulation as well as ordinary PCA to demonstrate its benefits.