 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Graph Neural Network Training Efficiency by Constructing Training Sets with Noise-Susceptible Samples
Dec 21, 2024


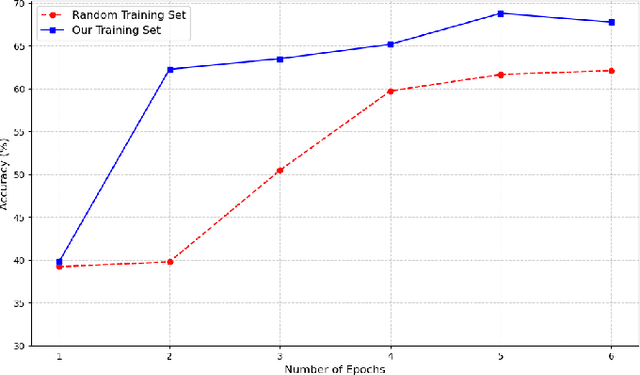
Graph Neural Networks (GNNs) are among the most powerful neural network architectures currently available. Unlike traditional neural networks that solely rely on the feature vector of the data to be processed as input, GNNs utilize both the graph that represents the relationships between data points and the feature matrix of the data to optimize their feature representation. This unique capability allows GNNs to achieve superior performance in various tasks. However, GNNs are highly susceptible to noise, which can significantly degrade their performance in common tasks such as classification and prediction. This paper proposes a novel approach leveraging spectral analysis to identify and select the points most sensitive to noise for constructing the training set. By training GNNs on these noise-sensitive points, experimental results demonstrate a substantial improvement in training efficiency compared to using randomly selected training sets.
Boosting GNN Performance via Training Sample Selection Based on Adversarial Robustness Evaluation
Dec 19, 2024Graph Neural Networks (GNNs) have established themselves as one of the most powerful neural network architectures, excelling in leveraging graph topology and node features for various tasks. However, GNNs are inherently vulnerable to noise in their inputs. Such noise can significantly degrade their performance. To address this challenge, we propose a novel approach that employs adversarial robustness evaluation techniques to identify nodes in the graph that are most susceptible to noise. By selecting and constructing a training set composed of these particularly noise-prone nodes, we then use them to train a Graph Convolutional Network (GCN). Our experimental results demonstrate that this strategy leads to substantial improvements in the GCN's performance.
Improving Graph Neural Networks via Adversarial Robustness Evaluation
Dec 14, 2024
Graph Neural Networks (GNNs) are currently one of the most powerful types of neural network architectures. Their advantage lies in the ability to leverage both the graph topology, which represents the relationships between samples, and the features of the samples themselves. However, the given graph topology often contains noisy edges, and GNNs are vulnerable to noise in the graph structure. This issue remains unresolved. In this paper, we propose using adversarial robustness evaluation to select a small subset of robust nodes that are less affected by noise. We then only feed the features of these robust nodes, along with the KNN graph constructed from these nodes, into the GNN for classification. Additionally, we compute the centroids for each class. For the remaining non-robust nodes, we assign them to the class whose centroid is closest to them. Experimental results show that this method significantly improves the accuracy of GNNs.
Enabling DBSCAN for Very Large-Scale High-Dimensional Spaces
Dec 03, 2024DBSCAN is one of the most important non-parametric unsupervised data analysis tools. By applying DBSCAN to a dataset, two key analytical results can be obtained: (1) clustering data points based on density distribution and (2) identifying outliers in the dataset. However, the time complexity of the DBSCAN algorithm is $O(n^2 \beta)$, where $n$ is the number of data points and $\beta = O(D)$, with $D$ representing the dimensionality of the data space. As a result, DBSCAN becomes computationally infeasible when both $n$ and $D$ are large. In this paper, we propose a DBSCAN method based on spectral data compression, capable of efficiently processing datasets with a large number of data points ($n$) and high dimensionality ($D$). By preserving only the most critical structural information during the compression process, our method effectively removes substantial redundancy and noise. Consequently, the solution quality of DBSCAN is significantly improved, enabling more accurate and reliable results.
Accelerating UMAP for Large-Scale Datasets Through Spectral Coarsening
Nov 19, 2024This paper introduces an innovative approach to dramatically accelerate UMAP using spectral data compression.The proposed method significantly reduces the size of the dataset, preserving its essential manifold structure through an advanced spectral compression technique. This allows UMAP to perform much faster while maintaining the quality of its embeddings. Experiments on real-world datasets, such as USPS, demonstrate the method's ability to achieve substantial data reduction without compromising embedding fidelity.
Towards fast DBSCAN via Spectrum-Preserving Data Compression
Nov 18, 2024This paper introduces a novel method to significantly accelerate DBSCAN by employing spectral data compression. The proposed approach reduces the size of the data set by a factor of five while preserving the essential clustering characteristics through an innovative spectral compression technique. This enables DBSCAN to run substantially faster without any loss of accuracy. Experiments on real-world data sets, such as USPS, demonstrate the method's capability to achieve this dramatic reduction in data size while maintaining clustering performance.
Addressing Noise and Efficiency Issues in Graph-Based Machine Learning Models From the Perspective of Adversarial Attack
Jan 28, 2024


Given that no existing graph construction method can generate a perfect graph for a given dataset, graph-based algorithms are invariably affected by the plethora of redundant and erroneous edges present within the constructed graphs. In this paper, we propose treating these noisy edges as adversarial attack and use a spectral adversarial robustness evaluation method to diminish the impact of noisy edges on the performance of graph algorithms. Our method identifies those points that are less vulnerable to noisy edges and leverages only these robust points to perform graph-based algorithms. Our experiments with spectral clustering, one of the most representative and widely utilized graph algorithms, reveal that our methodology not only substantially elevates the precision of the algorithm but also greatly accelerates its computational efficiency by leveraging only a select number of robust data points.
Improving Collaborative Filtering Recommendation via Graph Learning
Nov 06, 2023Recommendation systems are designed to provide personalized predictions for items that are most appealing to individual customers. Among various types of recommendation algorithms, k-nearest neighbor based collaborative filtering algorithm attracts tremendous attention and are widely used in practice. However, the k-nearest neighbor scheme can only capture the local relationship among users and the uniform neighborhood size is also not suitable to represent the underlying data structure. In this paper, we leverage emerging graph signal processing (GSP) theory to construct sparse yet high quality graph to enhance the solution quality and efficiency of collaborative filtering algorithm. Experimental results show that our method outperforms k-NN based collaborative filtering algorithm by a large margin on the benchmark data set.
Towards High-Performance Exploratory Data Analysis (EDA) Via Stable Equilibrium Point
Jun 07, 2023


Exploratory data analysis (EDA) is a vital procedure for data science projects. In this work, we introduce a stable equilibrium point (SEP) - based framework for improving the efficiency and solution quality of EDA. By exploiting the SEPs to be the representative points, our approach aims to generate high-quality clustering and data visualization for large-scale data sets. A very unique property of the proposed method is that the SEPs will directly encode the clustering properties of data sets. Compared with prior state-of-the-art clustering and data visualization methods, the proposed methods allow substantially improving computing efficiency and solution quality for large-scale data analysis tasks.
Accelerate Support Vector Clustering via Spectrum-Preserving Data Compression
Apr 21, 2023



Support vector clustering is an important clustering method. However, it suffers from a scalability issue due to its computational expensive cluster assignment step. In this paper we accelertate the support vector clustering via spectrum-preserving data compression. Specifically, we first compress the original data set into a small amount of spectrally representative aggregated data points. Then, we perform standard support vector clustering on the compressed data set. Finally, we map the clustering results of the compressed data set back to discover the clusters in the original data set. Our extensive experimental results on real-world data set demonstrate dramatically speedups over standard support vector clustering without sacrificing clustering quality.