 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Properties of Training & Generalization
Jun 18, 2026Deep learning has managed to evade numerous intuitions from classical statistics to achieve unprecedented performance on a number of real-world tasks. In this article, we investigate the key features and surprises of deep learning from a physics-informed perspective, taking care to point out and justify where possible the many choices inherent in constructing a deep learning model. In particular, we review the phenomenon of neural scaling laws and discuss their interplay with the constraints and inductive biases which may be present when applying machine learning to problems in physics.
Generative models on phase space
Apr 02, 2026Deep generative models such as diffusion and flow matching are powerful machine learning tools capable of learning and sampling from high-dimensional distributions. They are particularly useful when the training data appears to be concentrated on a submanifold of the data embedding space. For high-energy physics data, consisting of collections of relativistic energy-momentum 4-vectors, this submanifold can enforce extremely strong physically-motivated priors, such as energy and momentum conservation. If these constraints are learned only approximately, rather than exactly, this can inhibit the interpretability and reliability of such generative models. To remedy this deficiency, we introduce generative models which are, by construction, confined at every step of their sampling trajectory to the manifold of massless N-particle Lorentz-invariant phase space in the center-of-momentum frame. In the case of diffusion models, the "pure noise" forward process endpoint corresponds to the uniform distribution on phase space, which provides a clear starting point from which to identify how correlations among the particles emerge during the reverse (de-noising) process. We demonstrate that our models are able to learn both few-particle and many-particle distributions with various singularity structures, paving the way for future interpretability studies using generative models trained on simulated jet data.
Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
Oct 01, 2025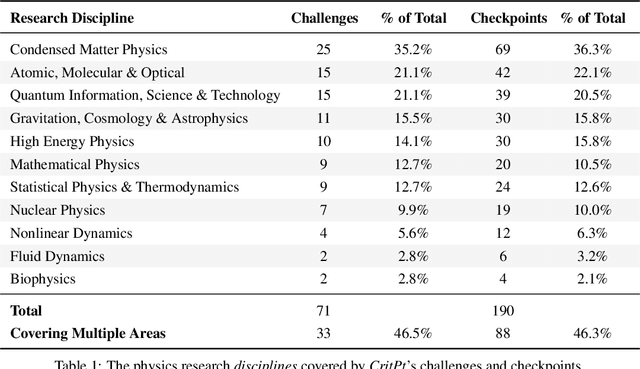
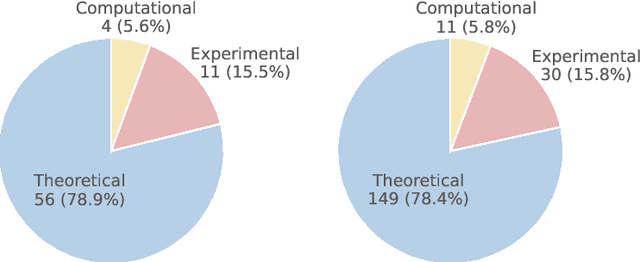
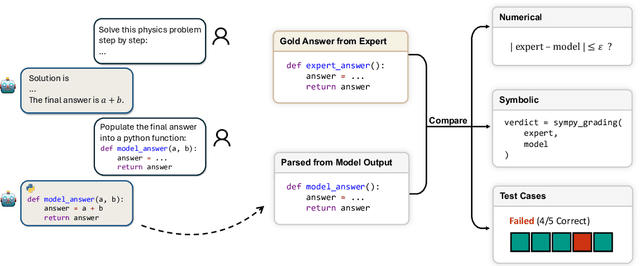

While large language models (LLMs) with reasoning capabilities are progressing rapidly on high-school math competitions and coding, can they reason effectively through complex, open-ended challenges found in frontier physics research? And crucially, what kinds of reasoning tasks do physicists want LLMs to assist with? To address these questions, we present the CritPt (Complex Research using Integrated Thinking - Physics Test, pronounced "critical point"), the first benchmark designed to test LLMs on unpublished, research-level reasoning tasks that broadly covers modern physics research areas, including condensed matter, quantum physics, atomic, molecular & optical physics, astrophysics, high energy physics, mathematical physics, statistical physics, nuclear physics, nonlinear dynamics, fluid dynamics and biophysics. CritPt consists of 71 composite research challenges designed to simulate full-scale research projects at the entry level, which are also decomposed to 190 simpler checkpoint tasks for more fine-grained insights. All problems are newly created by 50+ active physics researchers based on their own research. Every problem is hand-curated to admit a guess-resistant and machine-verifiable answer and is evaluated by an automated grading pipeline heavily customized for advanced physics-specific output formats. We find that while current state-of-the-art LLMs show early promise on isolated checkpoints, they remain far from being able to reliably solve full research-scale challenges: the best average accuracy among base models is only 4.0% , achieved by GPT-5 (high), moderately rising to around 10% when equipped with coding tools. Through the realistic yet standardized evaluation offered by CritPt, we highlight a large disconnect between current model capabilities and realistic physics research demands, offering a foundation to guide the development of scientifically grounded AI tools.
Contrastive Normalizing Flows for Uncertainty-Aware Parameter Estimation
May 13, 2025Estimating physical parameters from data is a crucial application of machine learning (ML) in the physical sciences. However, systematic uncertainties, such as detector miscalibration, induce data distribution distortions that can erode statistical precision. In both high-energy physics (HEP) and broader ML contexts, achieving uncertainty-aware parameter estimation under these domain shifts remains an open problem. In this work, we address this challenge of uncertainty-aware parameter estimation for a broad set of tasks critical for HEP. We introduce a novel approach based on Contrastive Normalizing Flows (CNFs), which achieves top performance on the HiggsML Uncertainty Challenge dataset. Building on the insight that a binary classifier can approximate the model parameter likelihood ratio, we address the practical limitations of expressivity and the high cost of simulating high-dimensional parameter grids by embedding data and parameters in a learned CNF mapping. This mapping yields a tunable contrastive distribution that enables robust classification under shifted data distributions. Through a combination of theoretical analysis and empirical evaluations, we demonstrate that CNFs, when coupled with a classifier and established frequentist techniques, provide principled parameter estimation and uncertainty quantification through classification that is robust to data distribution distortions.
Uncertainty Quantification From Scaling Laws in Deep Neural Networks
Mar 07, 2025



Quantifying the uncertainty from machine learning analyses is critical to their use in the physical sciences. In this work we focus on uncertainty inherited from the initialization distribution of neural networks. We compute the mean $\mu_{\mathcal{L}}$ and variance $\sigma_{\mathcal{L}}^2$ of the test loss $\mathcal{L}$ for an ensemble of multi-layer perceptrons (MLPs) with neural tangent kernel (NTK) initialization in the infinite-width limit, and compare empirically to the results from finite-width networks for three example tasks: MNIST classification, CIFAR classification and calorimeter energy regression. We observe scaling laws as a function of training set size $N_\mathcal{D}$ for both $\mu_{\mathcal{L}}$ and $\sigma_{\mathcal{L}}$, but find that the coefficient of variation $\epsilon_{\mathcal{L}} \equiv \sigma_{\mathcal{L}}/\mu_{\mathcal{L}}$ becomes independent of $N_\mathcal{D}$ at both infinite and finite width for sufficiently large $N_\mathcal{D}$. This implies that the coefficient of variation of a finite-width network may be approximated by its infinite-width value, and may in principle be calculable using finite-width perturbation theory.
Scaling Laws in Jet Classification
Dec 04, 2023We demonstrate the emergence of scaling laws in the benchmark top versus QCD jet classification problem in collider physics. Six distinct physically-motivated classifiers exhibit power-law scaling of the binary cross-entropy test loss as a function of training set size, with distinct power law indices. This result highlights the importance of comparing classifiers as a function of dataset size rather than for a fixed training set, as the optimal classifier may change considerably as the dataset is scaled up. We speculate on the interpretation of our results in terms of previous models of scaling laws observed in natural language and image datasets.
Feature Learning and Generalization in Deep Networks with Orthogonal Weights
Oct 11, 2023



Fully-connected deep neural networks with weights initialized from independent Gaussian distributions can be tuned to criticality, which prevents the exponential growth or decay of signals propagating through the network. However, such networks still exhibit fluctuations that grow linearly with the depth of the network, which may impair the training of networks with width comparable to depth. We show analytically that rectangular networks with tanh activations and weights initialized from the ensemble of orthogonal matrices have corresponding preactivation fluctuations which are independent of depth, to leading order in inverse width. Moreover, we demonstrate numerically that, at initialization, all correlators involving the neural tangent kernel (NTK) and its descendants at leading order in inverse width -- which govern the evolution of observables during training -- saturate at a depth of $\sim 20$, rather than growing without bound as in the case of Gaussian initializations. We speculate that this structure preserves finite-width feature learning while reducing overall noise, thus improving both generalization and training speed. We provide some experimental justification by relating empirical measurements of the NTK to the superior performance of deep nonlinear orthogonal networks trained under full-batch gradient descent on the MNIST and CIFAR-10 classification tasks.
Topological Obstructions to Autoencoding
Feb 16, 2021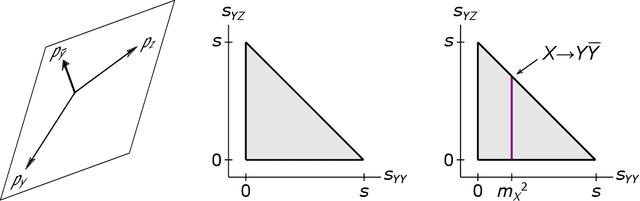

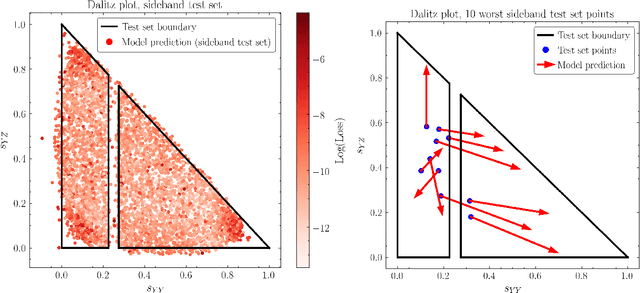
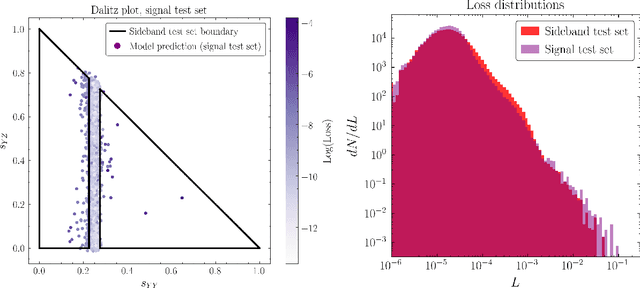
Autoencoders have been proposed as a powerful tool for model-independent anomaly detection in high-energy physics. The operating principle is that events which do not belong to the space of training data will be reconstructed poorly, thus flagging them as anomalies. We point out that in a variety of examples of interest, the connection between large reconstruction error and anomalies is not so clear. In particular, for data sets with nontrivial topology, there will always be points that erroneously seem anomalous due to global issues. Conversely, neural networks typically have an inductive bias or prior to locally interpolate such that undersampled or rare events may be reconstructed with small error, despite actually being the desired anomalies. Taken together, these facts are in tension with the simple picture of the autoencoder as an anomaly detector. Using a series of illustrative low-dimensional examples, we show explicitly how the intrinsic and extrinsic topology of the dataset affects the behavior of an autoencoder and how this topology is manifested in the latent space representation during training. We ground this analysis in the discussion of a mock "bump hunt" in which the autoencoder fails to identify an anomalous "signal" for reasons tied to the intrinsic topology of $n$-particle phase space.