 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerspectives for Direct Interpretability in Multi-Agent Deep Reinforcement Learning
Feb 02, 2025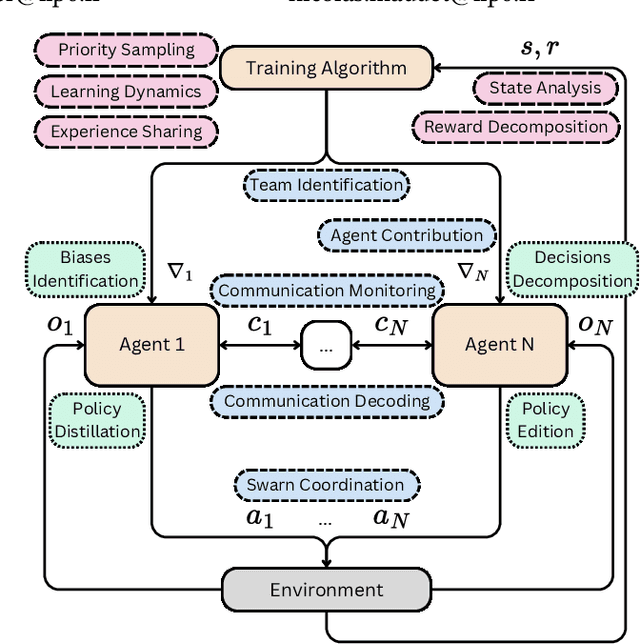
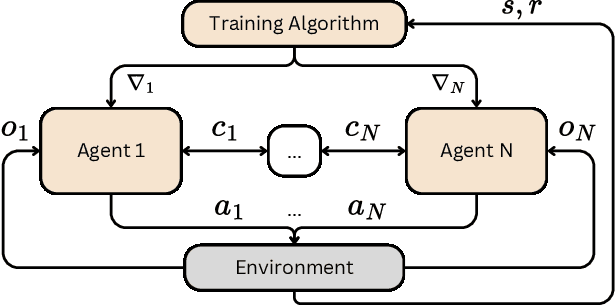
Multi-Agent Deep Reinforcement Learning (MADRL) was proven efficient in solving complex problems in robotics or games, yet most of the trained models are hard to interpret. While learning intrinsically interpretable models remains a prominent approach, its scalability and flexibility are limited in handling complex tasks or multi-agent dynamics. This paper advocates for direct interpretability, generating post hoc explanations directly from trained models, as a versatile and scalable alternative, offering insights into agents' behaviour, emergent phenomena, and biases without altering models' architectures. We explore modern methods, including relevance backpropagation, knowledge edition, model steering, activation patching, sparse autoencoders and circuit discovery, to highlight their applicability to single-agent, multi-agent, and training process challenges. By addressing MADRL interpretability, we propose directions aiming to advance active topics such as team identification, swarm coordination and sample efficiency.
Contrastive Sparse Autoencoders for Interpreting Planning of Chess-Playing Agents
Jun 06, 2024



AI led chess systems to a superhuman level, yet these systems heavily rely on black-box algorithms. This is unsustainable in ensuring transparency to the end-user, particularly when these systems are responsible for sensitive decision-making. Recent interpretability work has shown that the inner representations of Deep Neural Networks (DNNs) were fathomable and contained human-understandable concepts. Yet, these methods are seldom contextualised and are often based on a single hidden state, which makes them unable to interpret multi-step reasoning, e.g. planning. In this respect, we propose contrastive sparse autoencoders (CSAE), a novel framework for studying pairs of game trajectories. Using CSAE, we are able to extract and interpret concepts that are meaningful to the chess-agent plans. We primarily focused on a qualitative analysis of the CSAE features before proposing an automated feature taxonomy. Furthermore, to evaluate the quality of our trained CSAE, we devise sanity checks to wave spurious correlations in our results.