 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Equilibrium Hypothesis: Rethinking implicit regularization in Deep Neural Networks
Oct 22, 2021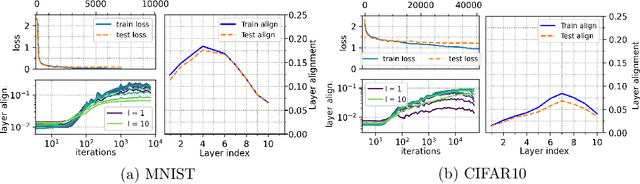
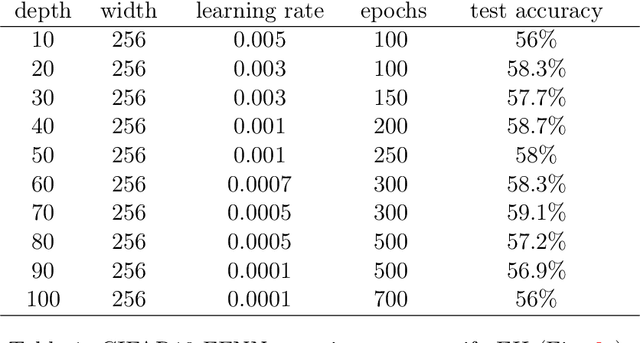
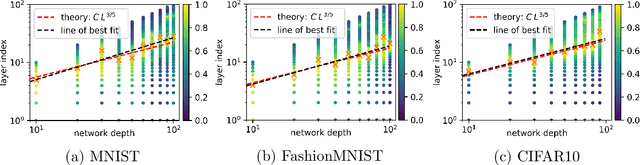
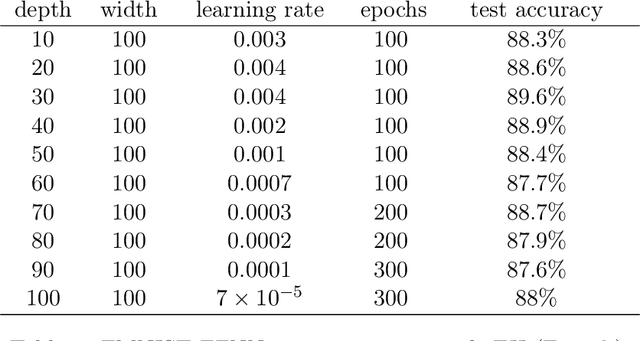
Modern Deep Neural Networks (DNNs) exhibit impressive generalization properties on a variety of tasks without explicit regularization, suggesting the existence of hidden regularization effects. Recent work by Baratin et al. (2021) sheds light on an intriguing implicit regularization effect, showing that some layers are much more aligned with data labels than other layers. This suggests that as the network grows in depth and width, an implicit layer selection phenomenon occurs during training. In this work, we provide the first explanation for this alignment hierarchy. We introduce and empirically validate the Equilibrium Hypothesis which states that the layers that achieve some balance between forward and backward information loss are the ones with the highest alignment to data labels. Our experiments demonstrate an excellent match with the theoretical predictions.