 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDerivatives and residual distribution of regularized M-estimators with application to adaptive tuning
Jul 11, 2021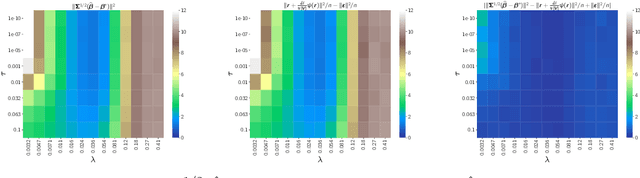
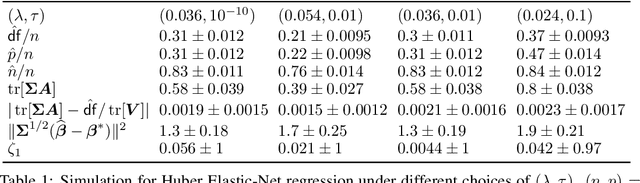
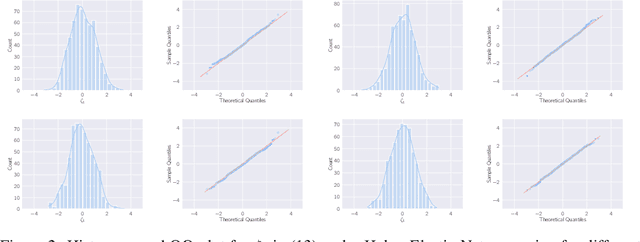
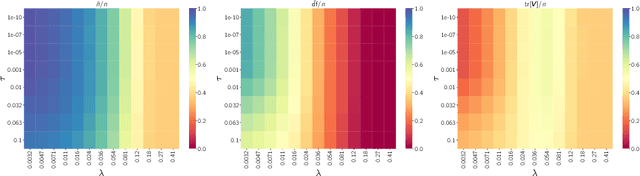
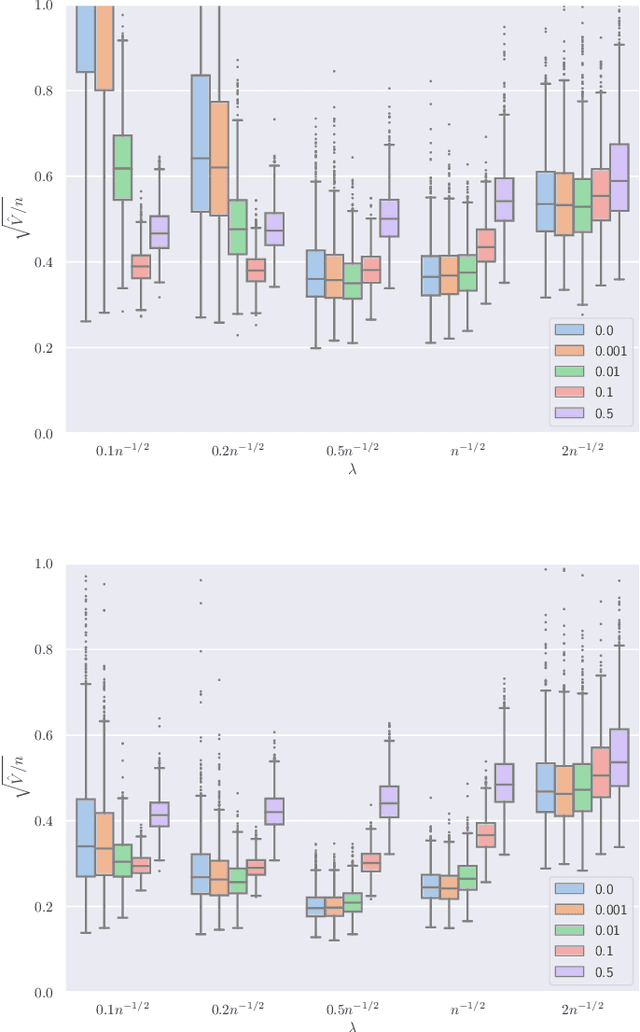
This paper studies M-estimators with gradient-Lipschitz loss function regularized with convex penalty in linear models with Gaussian design matrix and arbitrary noise distribution. A practical example is the robust M-estimator constructed with the Huber loss and the Elastic-Net penalty and the noise distribution has heavy-tails. Our main contributions are three-fold. (i) We provide general formulae for the derivatives of regularized M-estimators $\hat\beta(y,X)$ where differentiation is taken with respect to both $y$ and $X$; this reveals a simple differentiability structure shared by all convex regularized M-estimators. (ii) Using these derivatives, we characterize the distribution of the residual $r_i = y_i-x_i^\top\hat\beta$ in the intermediate high-dimensional regime where dimension and sample size are of the same order. (iii) Motivated by the distribution of the residuals, we propose a novel adaptive criterion to select tuning parameters of regularized M-estimators. The criterion approximates the out-of-sample error up to an additive constant independent of the estimator, so that minimizing the criterion provides a proxy for minimizing the out-of-sample error. The proposed adaptive criterion does not require the knowledge of the noise distribution or of the covariance of the design. Simulated data confirms the theoretical findings, regarding both the distribution of the residuals and the success of the criterion as a proxy of the out-of-sample error. Finally our results reveal new relationships between the derivatives of $\hat\beta(y,X)$ and the effective degrees of freedom of the M-estimator, which are of independent interest.
Asymptotic normality of robust $M$-estimators with convex penalty
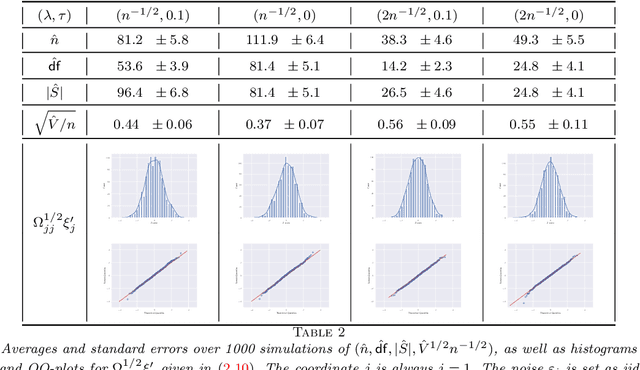
Jul 08, 2021

This paper develops asymptotic normality results for individual coordinates of robust M-estimators with convex penalty in high-dimensions, where the dimension $p$ is at most of the same order as the sample size $n$, i.e, $p/n\le\gamma$ for some fixed constant $\gamma>0$. The asymptotic normality requires a bias correction and holds for most coordinates of the M-estimator for a large class of loss functions including the Huber loss and its smoothed versions regularized with a strongly convex penalty. The asymptotic variance that characterizes the width of the resulting confidence intervals is estimated with data-driven quantities. This estimate of the variance adapts automatically to low ($p/n\to0)$ or high ($p/n \le \gamma$) dimensions and does not involve the proximal operators seen in previous works on asymptotic normality of M-estimators. For the Huber loss, the estimated variance has a simple expression involving an effective degrees-of-freedom as well as an effective sample size. The case of the Huber loss with Elastic-Net penalty is studied in details and a simulation study confirms the theoretical findings. The asymptotic normality results follow from Stein formulae for high-dimensional random vectors on the sphere developed in the paper which are of independent interest.