 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Block Linear System Solver Using Q-Learning Schduling for Unified Dynamic Power System Simulations
Oct 12, 2021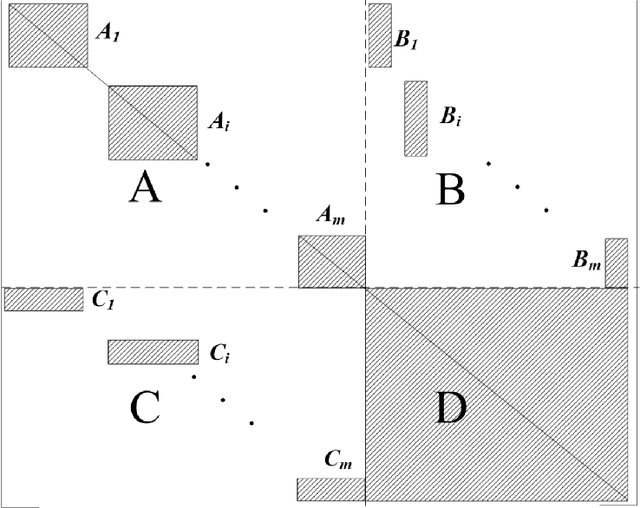
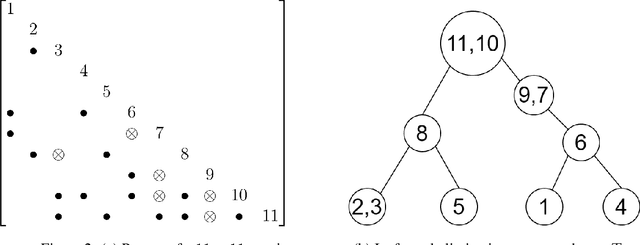
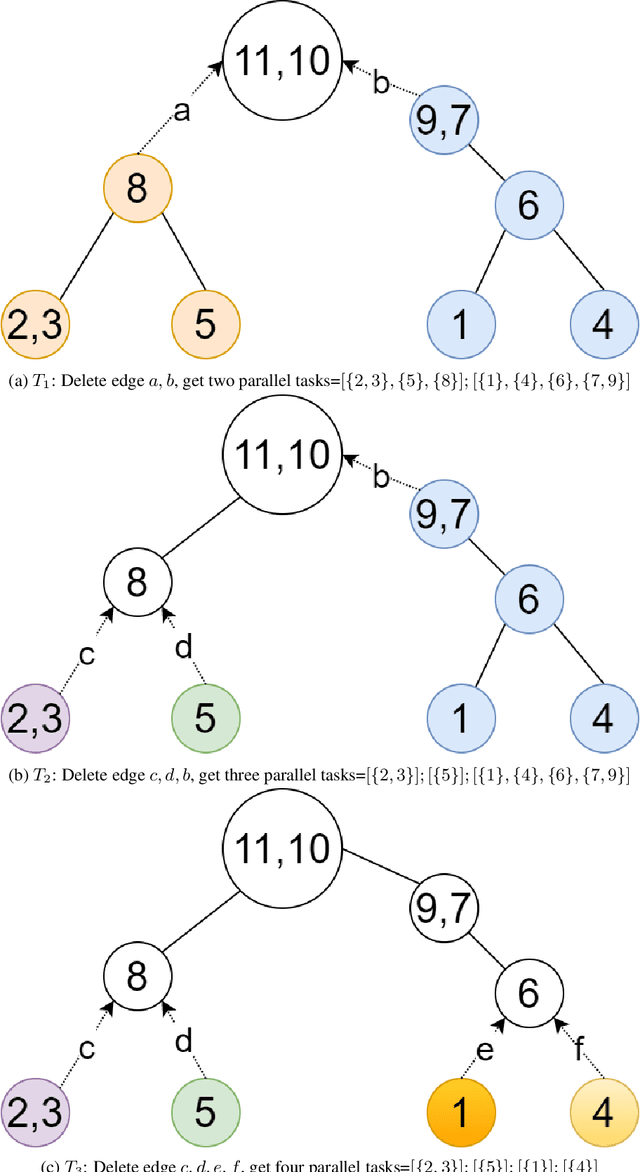
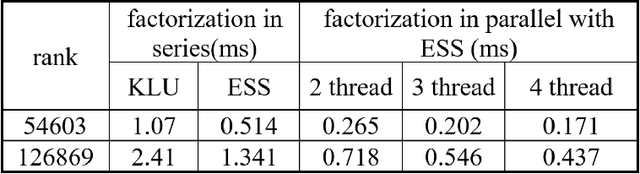
We present a fast block direct solver for the unified dynamic simulations of power systems. This solver uses a novel Q-learning based method for task scheduling. Unified dynamic simulations of power systems represent a method in which the electric-mechanical transient, medium-term and long-term dynamic phenomena are organically united. Due to the high rank and large numbers in solving, fast solution of these equations is the key to speeding up the simulation. The sparse systems of simulation contain complex nested block structure, which could be used by the solver to speed up. For the scheduling of blocks and frontals in the solver, we use a learning based task-tree scheduling technique in the framework of Markov Decision Process. That is, we could learn optimal scheduling strategies by offline training on many sample matrices. Then for any systems, the solver would get optimal task partition and scheduling on the learned model. Our learning-based algorithm could help improve the performance of sparse solver, which has been verified in some numerical experiments. The simulation on some large power systems shows that our solver is 2-6 times faster than KLU, which is the state-of-the-art sparse solver for circuit simulation problems.
Learning the Markov Decision Process in the Sparse Gaussian Elimination
Sep 30, 2021


We propose a learning-based approach for the sparse Gaussian Elimination. There are many hard combinatorial optimization problems in modern sparse solver. These NP-hard problems could be handled in the framework of Markov Decision Process, especially the Q-Learning technique. We proposed some Q-Learning algorithms for the main modules of sparse solver: minimum degree ordering, task scheduling and adaptive pivoting. Finally, we recast the sparse solver into the framework of Q-Learning. Our study is the first step to connect these two classical mathematical models: Gaussian Elimination and Markov Decision Process. Our learning-based algorithm could help improve the performance of sparse solver, which has been verified in some numerical experiments.
The Brownian motion in the transformer model
Jul 12, 2021Transformer is the state of the art model for many language and visual tasks. In this paper, we give a deep analysis of its multi-head self-attention (MHSA) module and find that: 1) Each token is a random variable in high dimensional feature space. 2) After layer normalization, these variables are mapped to points on the hyper-sphere. 3) The update of these tokens is a Brownian motion. The Brownian motion has special properties, its second order item should not be ignored. So we present a new second-order optimizer(an iterative K-FAC algorithm) for the MHSA module. In some short words: All tokens are mapped to high dimension hyper-sphere. The Scaled Dot-Product Attention $softmax(\frac{\mathbf{Q}\mathbf{K}^T}{\sqrt{d}})$ is just the Markov transition matrix for the random walking on the sphere. And the deep learning process would learn proper kernel function to get proper positions of these tokens. The training process in the MHSA module corresponds to a Brownian motion worthy of further study.
An iterative K-FAC algorithm for Deep Learning
Jan 01, 2021Kronecker-factored Approximate Curvature (K-FAC) method is a high efficiency second order optimizer for the deep learning. Its training time is less than SGD(or other first-order method) with same accuracy in many large-scale problems. The key of K-FAC is to approximates Fisher information matrix (FIM) as a block-diagonal matrix where each block is an inverse of tiny Kronecker factors. In this short note, we present CG-FAC -- an new iterative K-FAC algorithm. It uses conjugate gradient method to approximate the nature gradient. This CG-FAC method is matrix-free, that is, no need to generate the FIM matrix, also no need to generate the Kronecker factors A and G. We prove that the time and memory complexity of iterative CG-FAC is much less than that of standard K-FAC algorithm.
A short note on the decision tree based neural turing machine
Oct 27, 2020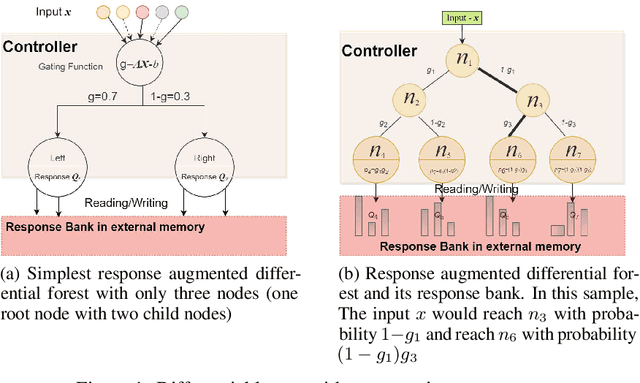
Turing machine and decision tree have developed independently for a long time. With the recent development of differentiable models, there is an intersection between them. Neural turing machine(NTM) opens door for the memory network. It use differentiable attention mechanism to read/write external memory bank. Differentiable forest brings differentiable properties to classical decision tree. In this short note, we show the deep connection between these two models. That is: differentiable forest is a special case of NTM. Differentiable forest is actually decision tree based neural turing machine. Based on this deep connection, we propose a response augmented differential forest (RaDF). The controller of RaDF is differentiable forest, the external memory of RaDF are response vectors which would be read/write by leaf nodes.
Attention augmented differentiable forest for tabular data
Oct 02, 2020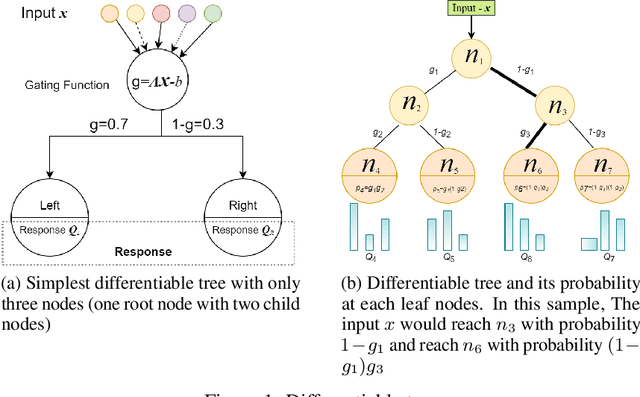

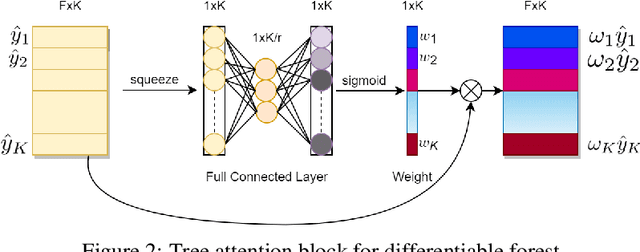
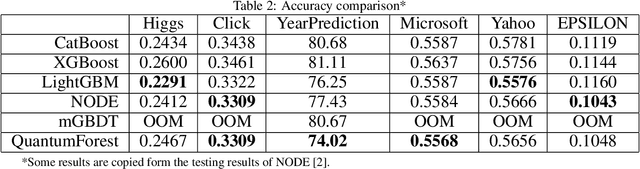
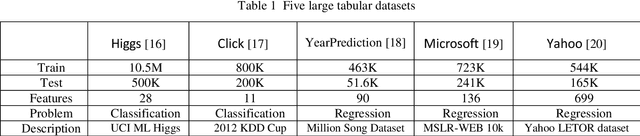
Differentiable forest is an ensemble of decision trees with full differentiability. Its simple tree structure is easy to use and explain. With full differentiability, it would be trained in the end-to-end learning framework with gradient-based optimization method. In this paper, we propose tree attention block(TAB) in the framework of differentiable forest. TAB block has two operations, squeeze and regulate. The squeeze operation would extract the characteristic of each tree. The regulate operation would learn nonlinear relations between these trees. So TAB block would learn the importance of each tree and adjust its weight to improve accuracy. Our experiment on large tabular dataset shows attention augmented differentiable forest would get comparable accuracy with gradient boosted decision trees(GBDT), which is the state-of-the-art algorithm for tabular datasets. And on some datasets, our model has higher accuracy than best GBDT libs (LightGBM, Catboost, and XGBoost). Differentiable forest model supports batch training and batch size is much smaller than the size of training set. So on larger data sets, its memory usage is much lower than GBDT model. The source codes are available at https://github.com/closest-git/QuantumForest.
Learning Unsplit-field-based PML for the FDTD Method by Deep Differentiable Forest
Apr 07, 2020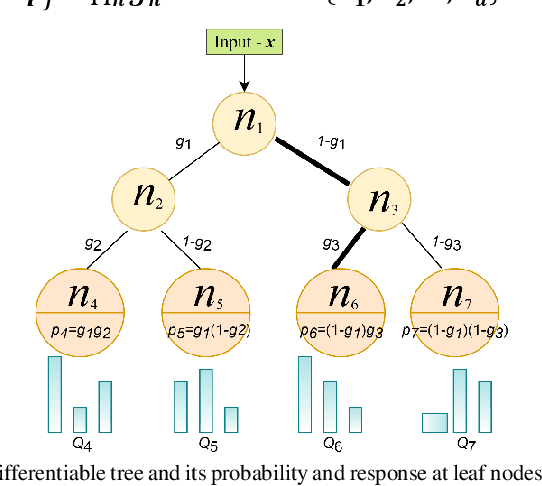

Alternative unsplit-filed-based absorbing boundary condition (ABC) computation approach for the finite-difference time-domain (FDTD) is efficiently proposed based on the deep differentiable forest. The deep differentiable forest (DDF) model is introduced to replace the conventional perfectly matched layer (PML) ABC during the computation process of FDTD. The field component data on the interface of traditional PML are adopted to train the DDF-based PML model. DDF has the advantages of both trees and neural networks. Its tree structure is easy to use and explain for the numerical PML data. It has full differentiability like neural networks. DDF could be trained by powerful techniques from deep learning. So compared to the traditional PML implementation, the proposed method can greatly reduce the size of FDTD physical domain and the calculation complexity of FDTD due to the novel model which only involves the one-cell thickness of boundary layer. Numerical simulations have been carried out to benchmark the performance of the proposed approach. Numerical results illustrate that the proposed method can not only easily replace the traditional PML, but also be integrated into the FDTD computation process with satisfactory numerical accuracy and compatibility to the FDTD.
Deep differentiable forest with sparse attention for the tabular data
Feb 29, 2020


We present a general architecture of deep differentiable forest and its sparse attention mechanism. The differentiable forest has the advantages of both trees and neural networks. Its structure is a simple binary tree, easy to use and understand. It has full differentiability and all variables are learnable parameters. We would train it by the gradient-based optimization method, which shows great power in the training of deep CNN. We find and analyze the attention mechanism in the differentiable forest. That is, each decision depends on only a few important features, and others are irrelevant. The attention is always sparse. Based on this observation, we improve its sparsity by data-aware initialization. We use the attribute importance to initialize the attention weight. Then the learned weight is much sparse than that from random initialization. Our experiment on some large tabular dataset shows differentiable forest has higher accuracy than GBDT, which is the state of art algorithm for tabular datasets. The source codes are available at https://github.com/closest-git/QuantumForest
LiteMORT: A memory efficient gradient boosting tree system on adaptive compact distributions
Jan 26, 2020



Gradient boosted decision trees (GBDT) is the leading algorithm for many commercial and academic data applications. We give a deep analysis of this algorithm, especially the histogram technique, which is a basis for the regulized distribution with compact support. We present three new modifications. 1) Share memory technique to reduce memory usage. In many cases, it only need the data source itself and no extra memory. 2) Implicit merging for "merge overflow problem"."merge overflow" means that merge some small datasets to huge datasets, which are too huge to be solved. By implicit merging, we just need the original small datasets to train the GBDT model. 3) Adaptive resize algorithm of histogram bins to improve accuracy. Experiments on two large Kaggle competitions verified our methods. They use much less memory than LightGBM and have higher accuracy. We have implemented these algorithms in an open-source package LiteMORT. The source codes are available at https://github.com/closest-git/LiteMORT
Express Wavenet -- a low parameter optical neural network with random shift wavelet pattern
Jan 06, 2020



Express Wavenet is an improved optical diffractive neural network. At each layer, it uses wavelet-like pattern to modulate the phase of optical waves. For input image with n2 pixels, express wavenet reduce parameter number from O(n2) to O(n). Only need one percent of the parameters, and the accuracy is still very high. In the MNIST dataset, it only needs 1229 parameters to get accuracy of 92%, while the standard optical network needs 125440 parameters. The random shift wavelets show the characteristics of optical network more vividly. Especially the vanishing gradient phenomenon in the training process. We present a modified expressway structure for this problem. Experiments verified the effect of random shift wavelet and expressway structure. Our work shows optical diffractive network would use much fewer parameters than other neural networks. The source codes are available at https://github.com/closest-git/ONNet.