 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling human intention inference in continuous 3D domains by inverse planning and body kinematics
Dec 02, 2021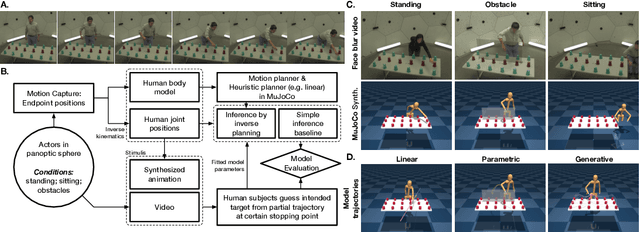
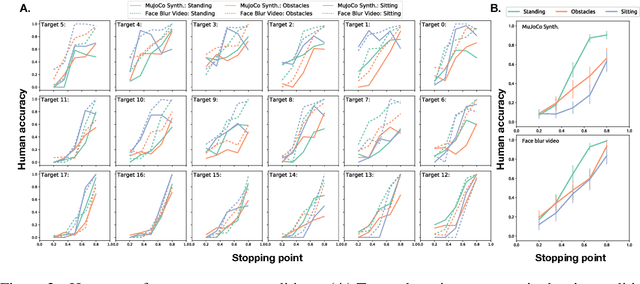
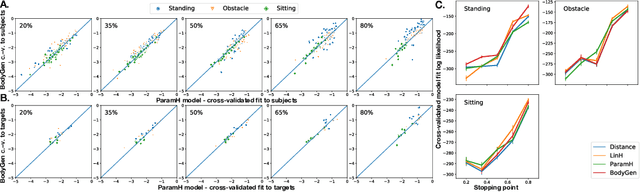
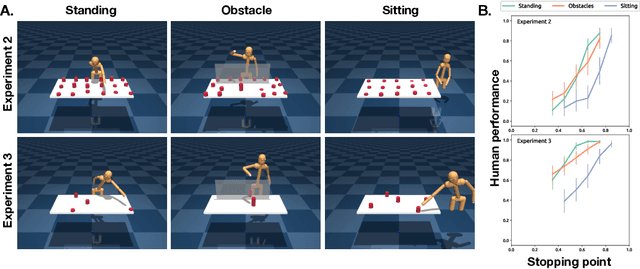
How to build AI that understands human intentions, and uses this knowledge to collaborate with people? We describe a computational framework for evaluating models of goal inference in the domain of 3D motor actions, which receives as input the 3D coordinates of an agent's body, and of possible targets, to produce a continuously updated inference of the intended target. We evaluate our framework in three behavioural experiments using a novel Target Reaching Task, in which human observers infer intentions of actors reaching for targets among distracts. We describe Generative Body Kinematics model, which predicts human intention inference in this domain using Bayesian inverse planning and inverse body kinematics. We compare our model to three heuristics, which formalize the principle of least effort using simple assumptions about the actor's constraints, without the use of inverse planning. Despite being more computationally costly, the Generative Body Kinematics model outperforms the heuristics in certain scenarios, such as environments with obstacles, and at the beginning of reaching actions while the actor is relatively far from the intended target. The heuristics make increasingly accurate predictions during later stages of reaching actions, such as, when the intended target is close, and can be inferred by extrapolating the wrist trajectory. Our results identify contexts in which inverse body kinematics is useful for intention inference. We show that human observers indeed rely on inverse body kinematics in such scenarios, suggesting that modeling body kinematic can improve performance of inference algorithms.