 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view knowledge distillation transformer for human action recognition
Mar 25, 2023



Recently, Transformer-based methods have been utilized to improve the performance of human action recognition. However, most of these studies assume that multi-view data is complete, which may not always be the case in real-world scenarios. Therefore, this paper presents a novel Multi-view Knowledge Distillation Transformer (MKDT) framework that consists of a teacher network and a student network. This framework aims to handle incomplete human action problems in real-world applications. Specifically, the multi-view knowledge distillation transformer uses a hierarchical vision transformer with shifted windows to capture more spatial-temporal information. Experimental results demonstrate that our framework outperforms the CNN-based method on three public datasets.
Breaking the Softmax Bottleneck for Sequential Recommender Systems with Dropout and Decoupling
Oct 11, 2021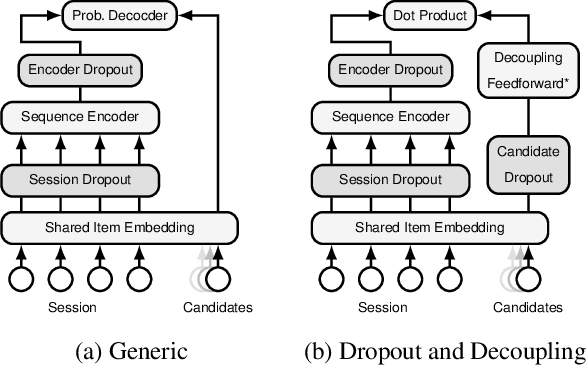

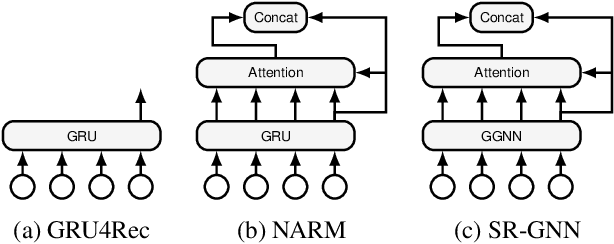
The Softmax bottleneck was first identified in language modeling as a theoretical limit on the expressivity of Softmax-based models. Being one of the most widely-used methods to output probability, Softmax-based models have found a wide range of applications, including session-based recommender systems (SBRSs). Softmax-based models consist of a Softmax function on top of a final linear layer. The bottleneck has been shown to be caused by rank deficiency in the final linear layer due to its connection with matrix factorization. In this paper, we show that there are more aspects to the Softmax bottleneck in SBRSs. Contrary to common beliefs, overfitting does happen in the final linear layer, while it is often associated with complex networks. Furthermore, we identified that the common technique of sharing item embeddings among session sequences and the candidate pool creates a tight-coupling that also contributes to the bottleneck. We propose a simple yet effective method, Dropout and Decoupling (D&D), to alleviate these problems. Our experiments show that our method significantly improves the accuracy of a variety of Softmax-based SBRS algorithms. When compared to other computationally expensive methods, such as MLP and MoS (Mixture of Softmaxes), our method performs on par with and at times even better than those methods, while keeping the same time complexity as Softmax-based models.