 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Training-Free Framework for Open-Vocabulary Image Segmentation and Recognition with EfficientNet and CLIP
Oct 22, 2025This paper presents a novel training-free framework for open-vocabulary image segmentation and object recognition (OVSR), which leverages EfficientNetB0, a convolutional neural network, for unsupervised segmentation and CLIP, a vision-language model, for open-vocabulary object recognition. The proposed framework adopts a two stage pipeline: unsupervised image segmentation followed by segment-level recognition via vision-language alignment. In the first stage, pixel-wise features extracted from EfficientNetB0 are decomposed using singular value decomposition to obtain latent representations, which are then clustered using hierarchical clustering to segment semantically meaningful regions. The number of clusters is adaptively determined by the distribution of singular values. In the second stage, the segmented regions are localized and encoded into image embeddings using the Vision Transformer backbone of CLIP. Text embeddings are precomputed using CLIP's text encoder from category-specific prompts, including a generic something else prompt to support open set recognition. The image and text embeddings are concatenated and projected into a shared latent feature space via SVD to enhance cross-modal alignment. Recognition is performed by computing the softmax over the similarities between the projected image and text embeddings. The proposed method is evaluated on standard benchmarks, including COCO, ADE20K, and PASCAL VOC, achieving state-of-the-art performance in terms of Hungarian mIoU, precision, recall, and F1-score. These results demonstrate the effectiveness, flexibility, and generalizability of the proposed framework.
Exploring PCA-based feature representations of image pixels via CNN to enhance food image segmentation
Nov 05, 2024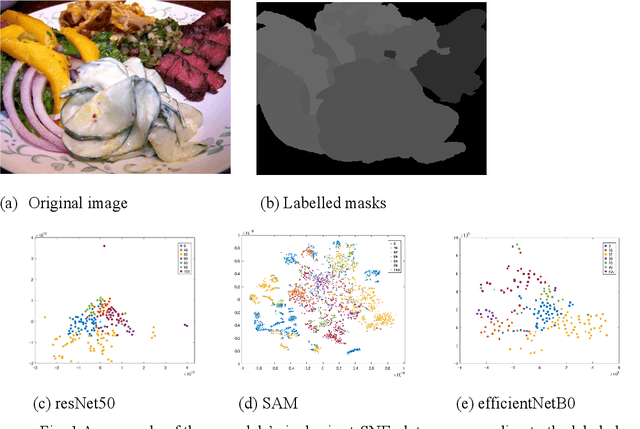

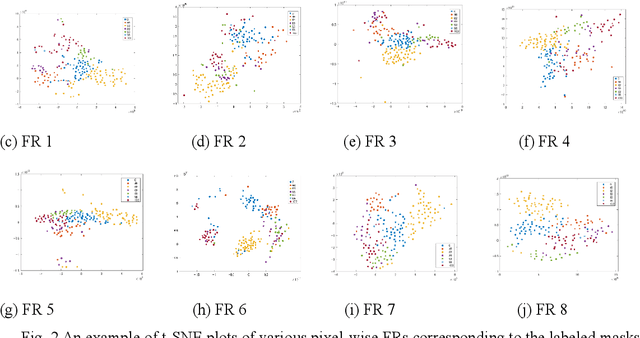

For open vocabulary recognition of ingredients in food images, segmenting the ingredients is a crucial step. This paper proposes a novel approach that explores PCA-based feature representations of image pixels using a convolutional neural network (CNN) to enhance segmentation. An internal clustering metric based on the silhouette score is defined to evaluate the clustering quality of various pixel-level feature representations generated by different feature maps derived from various CNN backbones. Using this metric, the paper explores optimal feature representation selection and suitable clustering methods for ingredient segmentation. Additionally, it is found that principal component (PC) maps derived from concatenations of backbone feature maps improve the clustering quality of pixel-level feature representations, resulting in stable segmentation outcomes. Notably, the number of selected eigenvalues can be used as the number of clusters to achieve good segmentation results. The proposed method performs well on the ingredient-labeled dataset FoodSeg103, achieving a mean Intersection over Union (mIoU) score of 0.5423. Importantly, the proposed method is unsupervised, and pixel-level feature representations from backbones are not fine-tuned on specific datasets. This demonstrates the flexibility, generalizability, and interpretability of the proposed method, while reducing the need for extensive labeled datasets.
Recognizing Multiple Ingredients in Food Images Using a Single-Ingredient Classification Model
Jan 26, 2024Recognizing food images presents unique challenges due to the variable spatial layout and shape changes of ingredients with different cooking and cutting methods. This study introduces an advanced approach for recognizing ingredients segmented from food images. The method localizes the candidate regions of the ingredients using the locating and sliding window techniques. Then, these regions are assigned into ingredient classes using a CNN (Convolutional Neural Network)-based single-ingredient classification model trained on a dataset of single-ingredient images. To address the challenge of processing speed in multi-ingredient recognition, a novel model pruning method is proposed that enhances the efficiency of the classification model. Subsequently, the multi-ingredient identification is achieved through a decision-making scheme, incorporating two novel algorithms. The single-ingredient image dataset, designed in accordance with the book entitled "New Food Ingredients List FOODS 2021", encompasses 9982 images across 110 diverse categories, emphasizing variety in ingredient shapes. In addition, a multi-ingredient image dataset is developed to rigorously evaluate the performance of our approach. Experimental results validate the effectiveness of our method, particularly highlighting its improved capability in recognizing multiple ingredients. This marks a significant advancement in the field of food image analysis.
Exploring CNN-based models for image's aesthetic score prediction with using ensemble
Oct 11, 2022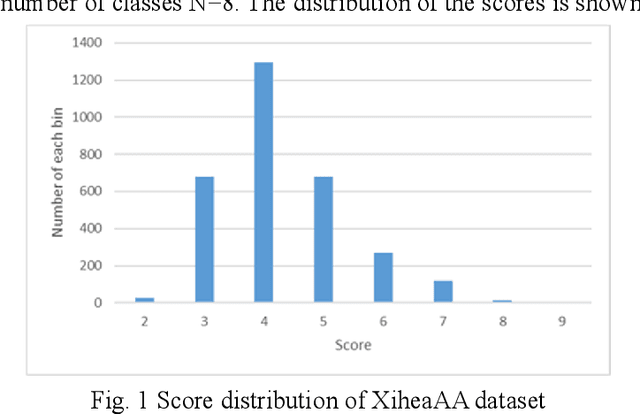
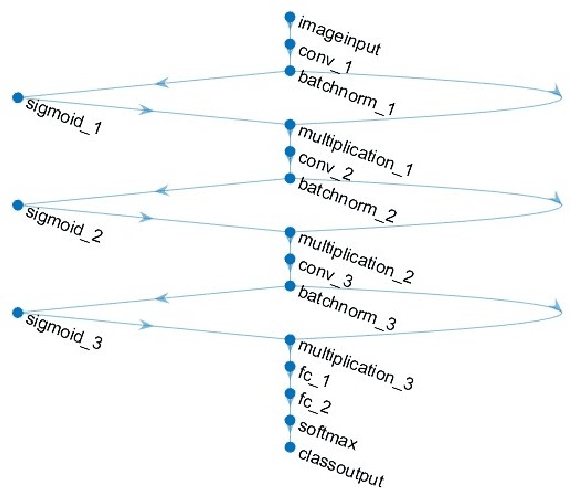
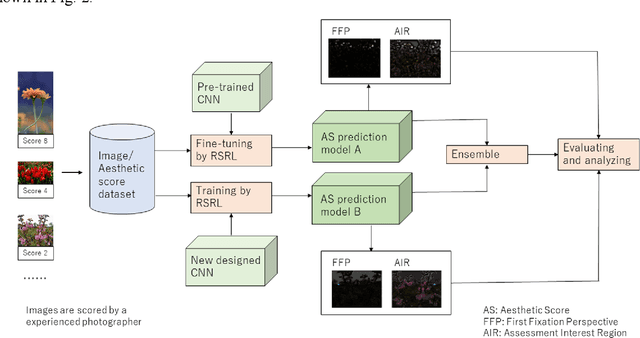

In this paper, we proposed a framework of constructing two types of the automatic image aesthetics assessment models with different CNN architectures and improving the performance of the image's aesthetic score prediction by the ensemble. Moreover, the attention regions of the models to the images are extracted to analyze the consistency with the subjects in the images. The experimental results verify that the proposed method is effective for improving the AS prediction. Moreover, it is found that the AS classification models trained on XiheAA dataset seem to learn the latent photography principles, although it can't be said that they learn the aesthetic sense.
Exploring to establish an appropriate model for image aesthetic assessment via CNN-based RSRL: An empirical study
Jun 28, 2021


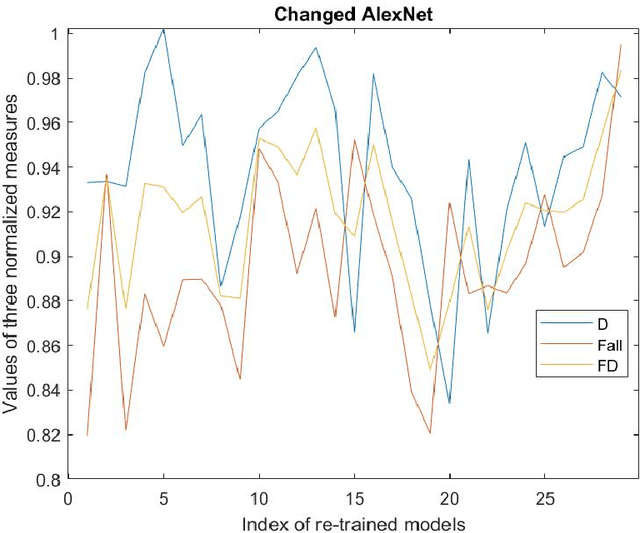
To establish an appropriate model for photo aesthetic assessment, in this paper, a D-measure which reflects the disentanglement degree of the final layer FC nodes of CNN is introduced. By combining F-measure with D-measure to obtain a FD measure, an algorithm of determining the optimal model from the multiple photo score prediction models generated by CNN-based repetitively self-revised learning(RSRL) is proposed. Furthermore, the first fixation perspective(FFP) and the assessment interest region(AIR) of the models are defined and calculated. The experimental results show that the FD measure is effective for establishing the appropriate model from the multiple score prediction models with different CNN structures. Moreover, the FD-determined optimal models with the comparatively high FD always have the FFP an AIR which are close to the human's aesthetic perception when enjoying photos.
CNN-based Repetitive self-revised learning for photos' aesthetics imbalanced classification
Mar 27, 2020



Aesthetic assessment is subjective, and the distribution of the aesthetic levels is imbalanced. In order to realize the auto-assessment of photo aesthetics, we focus on using repetitive self-revised learning (RSRL) to train the CNN-based aesthetics classification network by imbalanced data set. As RSRL, the network is trained repetitively by dropping out the low likelihood photo samples at the middle levels of aesthetics from the training data set based on the previously trained network. Further, the retained two networks are used in extracting highlight regions of the photos related with the aesthetic assessment. Experimental results show that the CNN-based repetitive self-revised learning is effective for improving the performances of the imbalanced classification.
Sample-specific repetitive learning for photo aesthetic assessment and highlight region extraction
Sep 18, 2019



Aesthetic assessment is subjective, and the distribution of the aesthetic levels is imbalanced. In order to realize the auto-assessment of photo aesthetics, we focus on retraining the CNN-based aesthetic assessment model by dropping out the unavailable samples in the middle levels from the training data set repetitively to overcome the effect of imbalanced aesthetic data on classification. Further, the method of extracting aesthetics highlight region of the photo image by using the two repetitively trained models is presented. Therefore, the correlation of the extracted region with the aesthetic levels is analyzed to illustrate what aesthetics features influence the aesthetic quality of the photo. Moreover, the testing data set is from the different data source called 500px. Experimental results show that the proposed method is effective.