 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction-Conditioned Risk Gating for Safety-Critical Control under Partial Observability
May 14, 2026Many safety-critical control problems are modeled as risk-sensitive partially observable Markov decision processes, where the controller must make decisions from incomplete observations while balancing task performance against safety risk. Although belief-space planning provides a principled solution, maintaining and planning over beliefs can be computationally costly and sensitive to model specification in practical domains. We propose a lightweight risk-gated reinforcement learning approximation for risk-sensitive control under partial observability. The method constructs a compact finite-history proxy state and learns an action-conditioned predictor of near-term safety violation. This predicted candidate-action risk is used in two complementary ways: as a risk penalty during value learning, and as a decision-time gate that interpolates between optimistic and conservative ensemble value estimates. As a result, low-risk actions are evaluated closer to reward-seeking estimates, while high-risk actions are evaluated more conservatively. We evaluate the approach in two safety-critical partially observable domains: automated glucose regulation and safety-constrained navigation. Across adult and adolescent glucose-control cohorts, the method improves overall glycemic tradeoffs and substantially reduces runtime relative to a belief-space planning baseline. On Safety-Gym navigation benchmarks, it achieves a more favorable reward-cost balance than unconstrained RL and several standard safe-RL baselines. These results suggest that action-conditioned near-term risk can provide an effective local signal for approximate risk-sensitive POMDP control when full belief-space planning is impractical.
Regression for matrix-valued data via Kronecker products factorization
Apr 30, 2024



We study the matrix-variate regression problem $Y_i = \sum_{k} \beta_{1k} X_i \beta_{2k}^{\top} + E_i$ for $i=1,2\dots,n$ in the high dimensional regime wherein the response $Y_i$ are matrices whose dimensions $p_{1}\times p_{2}$ outgrow both the sample size $n$ and the dimensions $q_{1}\times q_{2}$ of the predictor variables $X_i$ i.e., $q_{1},q_{2} \ll n \ll p_{1},p_{2}$. We propose an estimation algorithm, termed KRO-PRO-FAC, for estimating the parameters $\{\beta_{1k}\} \subset \Re^{p_1 \times q_1}$ and $\{\beta_{2k}\} \subset \Re^{p_2 \times q_2}$ that utilizes the Kronecker product factorization and rearrangement operations from Van Loan and Pitsianis (1993). The KRO-PRO-FAC algorithm is computationally efficient as it does not require estimating the covariance between the entries of the $\{Y_i\}$. We establish perturbation bounds between $\hat{\beta}_{1k} -\beta_{1k}$ and $\hat{\beta}_{2k} - \beta_{2k}$ in spectral norm for the setting where either the rows of $E_i$ or the columns of $E_i$ are independent sub-Gaussian random vectors. Numerical studies on simulated and real data indicate that our procedure is competitive, in terms of both estimation error and predictive accuracy, compared to other existing methods.
Classification of high-dimensional data with spiked covariance matrix structure
Oct 05, 2021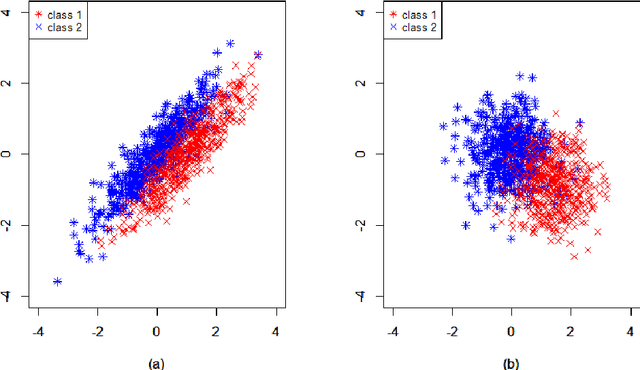
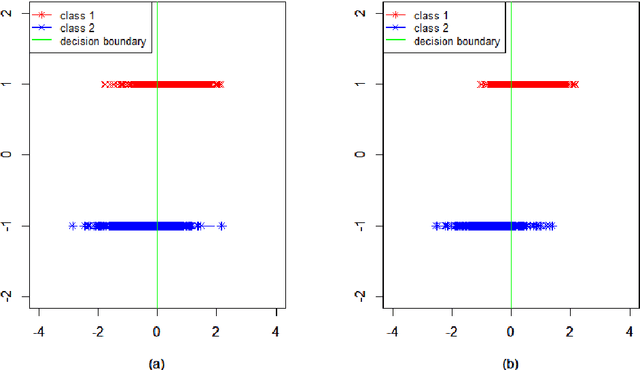
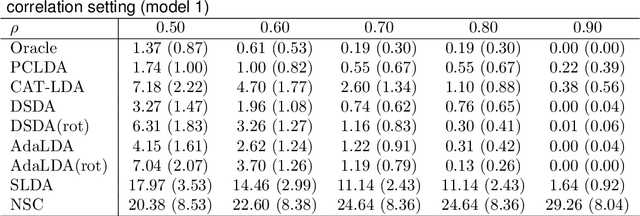
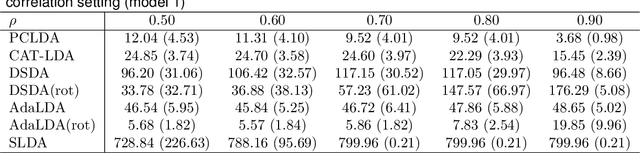
We study the classification problem for high-dimensional data with $n$ observations on $p$ features where the $p \times p$ covariance matrix $\Sigma$ exhibits a spiked eigenvalues structure and the vector $\zeta$, given by the difference between the whitened mean vectors, is sparse with sparsity at most $s$. We propose an adaptive classifier (adaptive with respect to the sparsity $s$) that first performs dimension reduction on the feature vectors prior to classification in the dimensionally reduced space, i.e., the classifier whitened the data, then screen the features by keeping only those corresponding to the $s$ largest coordinates of $\zeta$ and finally apply Fisher linear discriminant on the selected features. Leveraging recent results on entrywise matrix perturbation bounds for covariance matrices, we show that the resulting classifier is Bayes optimal whenever $n \rightarrow \infty$ and $s \sqrt{n^{-1} \ln p} \rightarrow 0$. Experimental results on real and synthetic data sets indicate that the proposed classifier is competitive with existing state-of-the-art methods while also selecting a smaller number of features.