 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Slot Attention for Vision-and-Language Navigation
Jun 22, 2022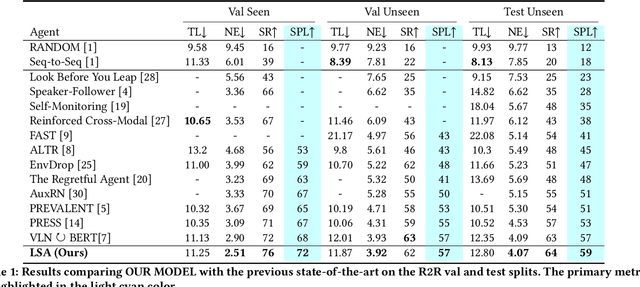
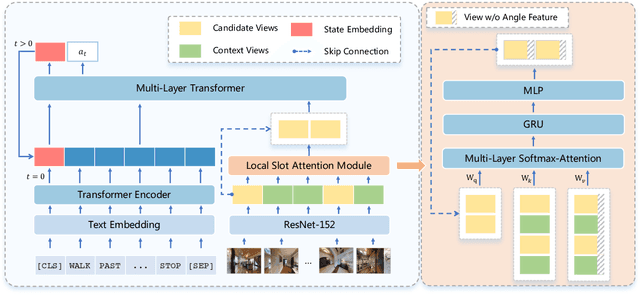
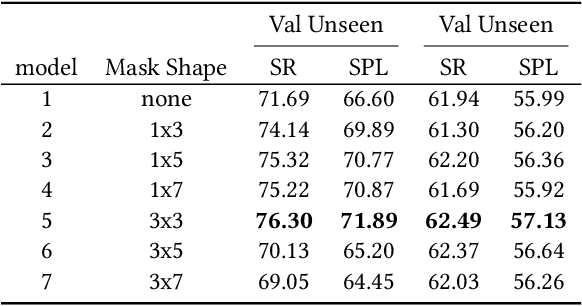

Vision-and-language navigation (VLN), a frontier study aiming to pave the way for general-purpose robots, has been a hot topic in the computer vision and natural language processing community. The VLN task requires an agent to navigate to a goal location following natural language instructions in unfamiliar environments. Recently, transformer-based models have gained significant improvements on the VLN task. Since the attention mechanism in the transformer architecture can better integrate inter- and intra-modal information of vision and language. However, there exist two problems in current transformer-based models. 1) The models process each view independently without taking the integrity of the objects into account. 2) During the self-attention operation in the visual modality, the views that are spatially distant can be inter-weaved with each other without explicit restriction. This kind of mixing may introduce extra noise instead of useful information. To address these issues, we propose 1) A slot-attention based module to incorporate information from segmentation of the same object. 2) A local attention mask mechanism to limit the visual attention span. The proposed modules can be easily plugged into any VLN architecture and we use the Recurrent VLN-Bert as our base model. Experiments on the R2R dataset show that our model has achieved the state-of-the-art results.