 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Drives Templates: Co-Speech Gesture Synthesis with Learned Templates
Aug 18, 2021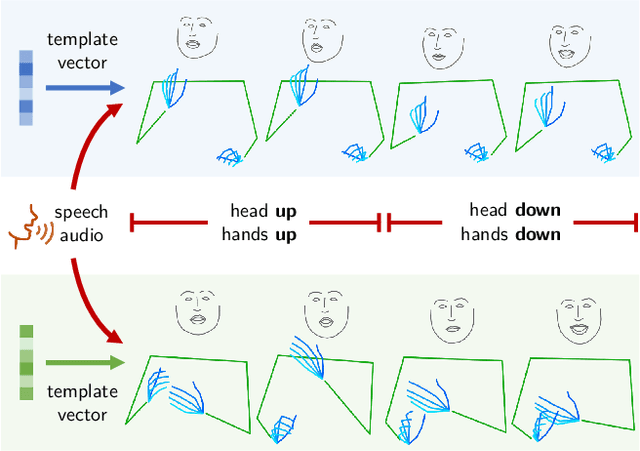
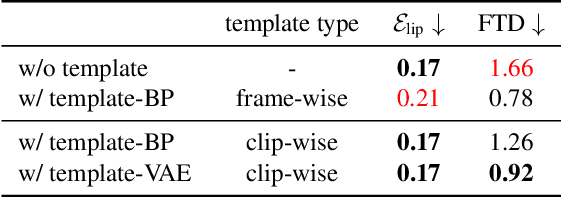


Co-speech gesture generation is to synthesize a gesture sequence that not only looks real but also matches with the input speech audio. Our method generates the movements of a complete upper body, including arms, hands, and the head. Although recent data-driven methods achieve great success, challenges still exist, such as limited variety, poor fidelity, and lack of objective metrics. Motivated by the fact that the speech cannot fully determine the gesture, we design a method that learns a set of gesture template vectors to model the latent conditions, which relieve the ambiguity. For our method, the template vector determines the general appearance of a generated gesture sequence, while the speech audio drives subtle movements of the body, both indispensable for synthesizing a realistic gesture sequence. Due to the intractability of an objective metric for gesture-speech synchronization, we adopt the lip-sync error as a proxy metric to tune and evaluate the synchronization ability of our model. Extensive experiments show the superiority of our method in both objective and subjective evaluations on fidelity and synchronization.