 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Gradient Boosting Machine
Jun 07, 2020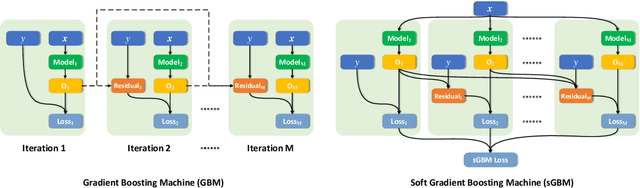
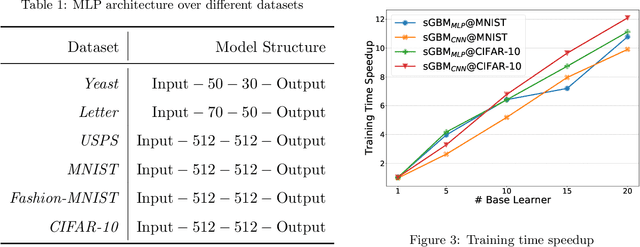


Gradient Boosting Machine has proven to be one successful function approximator and has been widely used in a variety of areas. However, since the training procedure of each base learner has to take the sequential order, it is infeasible to parallelize the training process among base learners for speed-up. In addition, under online or incremental learning settings, GBMs achieved sub-optimal performance due to the fact that the previously trained base learners can not adapt with the environment once trained. In this work, we propose the soft Gradient Boosting Machine (sGBM) by wiring multiple differentiable base learners together, by injecting both local and global objectives inspired from gradient boosting, all base learners can then be jointly optimized with linear speed-up. When using differentiable soft decision trees as base learner, such device can be regarded as an alternative version of the (hard) gradient boosting decision trees with extra benefits. Experimental results showed that, sGBM enjoys much higher time efficiency with better accuracy, given the same base learner in both on-line and off-line settings.