 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP^2-VL: Private Photo Dataset Protection by Data Poisoning for Vision-Language Models
Mar 25, 2026Recent advances in visual-language alignment have endowed vision-language models (VLMs) with fine-grained image understanding capabilities. However, this progress also introduces new privacy risks. This paper first proposes a novel privacy threat model named identity-affiliation learning: an attacker fine-tunes a VLM using only a few private photos of a target individual, thereby embedding associations between the target facial identity and their private property and social relationships into the model's internal representations. Once deployed via public APIs, this model enables unauthorized exposure of the target user's private information upon input of their photos. To benchmark VLMs' susceptibility to such identity-affiliation leakage, we introduce the first identity-affiliation dataset comprising seven typical scenarios appearing in private photos. Each scenario is instantiated with multiple identity-centered photo-description pairs. Experimental results demonstrate that mainstream VLMs like LLaVA, Qwen-VL, and MiniGPT-v2, can recognize facial identities and infer identity-affiliation relationships by fine-tuning on small-scale private photographic dataset, and even on synthetically generated datasets. To mitigate this privacy risk, we propose DP2-VL, the first Dataset Protection framework for private photos that leverages Data Poisoning. Though optimizing imperceptible perturbations by pushing the original representations toward an antithetical region, DP2-VL induces a dataset-level shift in the embedding space of VLMs'encoders. This shift separates protected images from clean inference images, causing fine-tuning on the protected set to overfit. Extensive experiments demonstrate that DP2-VL achieves strong generalization across models, robustness to diverse post-processing operations, and consistent effectiveness across varying protection ratios.
Agile Affine Frequency Division Multiplexing
Dec 16, 2025The advancement to 6G calls for waveforms that transcend static robustness to achieve intelligent adaptability. Affine Frequency Division Multiplexing (AFDM), despite its strength in doubly-dispersive channels, has been confined by chirp parameters optimized for worst-case scenarios. This paper shatters this limitation with Agile-AFDM, a novel framework that endows AFDM with dynamic, data-aware intelligence. By redefining chirp parameters as optimizable variables for each transmission block based on real-time channel and data information, Agile-AFDM transforms into an adaptive platform. It can actively reconfigure its waveform to minimize peak-to-average power ratio (PAPR) for power efficiency, suppress inter-carrier interference (ICI) for communication reliability, or reduce Cramer-Rao bound (CRLB) for sensing accuracy. This paradigm shift from a static, one-size-fits-all waveform to a context-aware signal designer is made practical by efficient, tailored optimization algorithms. Comprehensive simulations demonstrate that this capability delivers significant performance gains across all metrics, surpassing conventional OFDM and static AFDM. Agile-AFDM, therefore, offers a crucial step forward in the design of agile waveforms for 6G and beyond.
Fractional Fourier Domain PAPR Reduction
Nov 13, 2024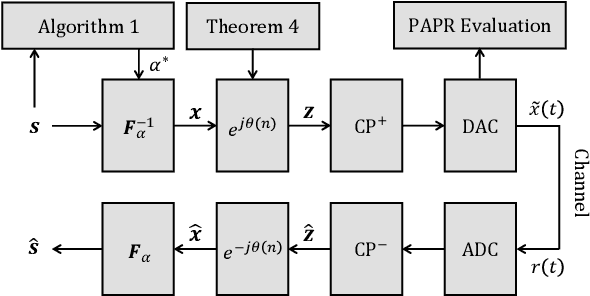



High peak-to-average power ratio (PAPR) has long posed a challenge for multi-carrier systems, impacting amplifier efficiency and overall system performance. This paper introduces dynamic angle fractional Fourier division multiplexing (DA-FrFDM), an innovative multi-carrier system that effectively reduces PAPR for both QAM and Gaussian signals with minimal signaling overhead. DA-FrFDM leverages the fractional Fourier domain to balance PAPR characteristics between the time and frequency domains, achieving significant PAPR reduction while preserving signal quality. Furthermore, DA-FrFDM refines signal processing and enables one-tap equalization in the fractional Fourier domain through the simple multiplication of time-domain signals by a quadratic phase sequence. Our results show that DA-FrFDM not only outperforms existing PAPR reduction techniques but also retains efficient inter-carrier interference (ICI) mitigation capabilities in doubly dispersive channels.
Pyramid Multi-branch Fusion DCNN with Multi-Head Self-Attention for Mandarin Speech Recognition
Mar 23, 2023



As one of the major branches of automatic speech recognition, attention-based models greatly improves the feature representation ability of the model. In particular, the multi-head mechanism is employed in the attention, hoping to learn speech features of more aspects in different attention subspaces. For speech recognition of complex languages, on the one hand, a small head size will lead to an obvious shortage of learnable aspects. On the other hand, we need to reduce the dimension of each subspace to keep the size of the overall feature space unchanged when we increase the number of heads, which will significantly weaken the ability to represent the feature of each subspace. Therefore, this paper explores how to use a small attention subspace to represent complete speech features while ensuring many heads. In this work we propose a novel neural network architecture, namely, pyramid multi-branch fusion DCNN with multi-head self-attention. The proposed architecture is inspired by Dilated Convolution Neural Networks (DCNN), it uses multiple branches with DCNN to extract the feature of the input speech under different receptive fields. To reduce the number of parameters, every two branches are merged until all the branches are merged into one. Thus, its shape is like a pyramid rotated 90 degrees. We demonstrate that on Aishell-1, a widely used Mandarin speech dataset, our model achieves a character error rate (CER) of 6.45% on the test sets.