 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpected Harm: Rethinking Safety Evaluation of (Mis)Aligned LLMs
Feb 02, 2026Current evaluations of LLM safety predominantly rely on severity-based taxonomies to assess the harmfulness of malicious queries. We argue that this formulation requires re-examination as it assumes uniform risk across all malicious queries, neglecting Execution Likelihood--the conditional probability of a threat being realized given the model's response. In this work, we introduce Expected Harm, a metric that weights the severity of a jailbreak by its execution likelihood, modeled as a function of execution cost. Through empirical analysis of state-of-the-art models, we reveal a systematic Inverse Risk Calibration: models disproportionately exhibit stronger refusal behaviors for low-likelihood (high-cost) threats while remaining vulnerable to high-likelihood (low-cost) queries. We demonstrate that this miscalibration creates a structural vulnerability: by exploiting this property, we increase the attack success rate of existing jailbreaks by up to $2\times$. Finally, we trace the root cause of this failure using linear probing, which reveals that while models encode severity in their latent space to drive refusal decisions, they possess no distinguishable internal representation of execution cost, making them "blind" to this critical dimension of risk.
Eyes-on-Me: Scalable RAG Poisoning through Transferable Attention-Steering Attractors
Oct 01, 2025Existing data poisoning attacks on retrieval-augmented generation (RAG) systems scale poorly because they require costly optimization of poisoned documents for each target phrase. We introduce Eyes-on-Me, a modular attack that decomposes an adversarial document into reusable Attention Attractors and Focus Regions. Attractors are optimized to direct attention to the Focus Region. Attackers can then insert semantic baits for the retriever or malicious instructions for the generator, adapting to new targets at near zero cost. This is achieved by steering a small subset of attention heads that we empirically identify as strongly correlated with attack success. Across 18 end-to-end RAG settings (3 datasets $\times$ 2 retrievers $\times$ 3 generators), Eyes-on-Me raises average attack success rates from 21.9 to 57.8 (+35.9 points, 2.6$\times$ over prior work). A single optimized attractor transfers to unseen black box retrievers and generators without retraining. Our findings establish a scalable paradigm for RAG data poisoning and show that modular, reusable components pose a practical threat to modern AI systems. They also reveal a strong link between attention concentration and model outputs, informing interpretability research.
LLMs are Biased Evaluators But Not Biased for Retrieval Augmented Generation
Oct 28, 2024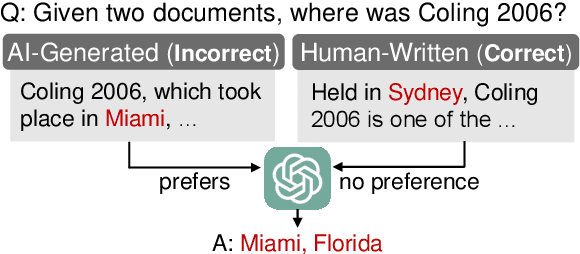
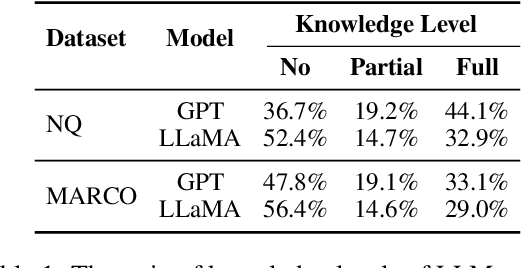
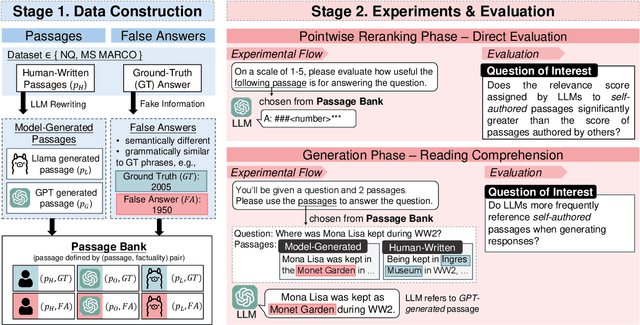

Recent studies have demonstrated that large language models (LLMs) exhibit significant biases in evaluation tasks, particularly in preferentially rating and favoring self-generated content. However, the extent to which this bias manifests in fact-oriented tasks, especially within retrieval-augmented generation (RAG) frameworks-where keyword extraction and factual accuracy take precedence over stylistic elements-remains unclear. Our study addresses this knowledge gap by simulating two critical phases of the RAG framework. In the first phase, we access the suitability of human-authored versus model-generated passages, emulating the pointwise reranking process. The second phase involves conducting pairwise reading comprehension tests to simulate the generation process. Contrary to previous findings indicating a self-preference in rating tasks, our results reveal no significant self-preference effect in RAG frameworks. Instead, we observe that factual accuracy significantly influences LLMs' output, even in the absence of prior knowledge. Our research contributes to the ongoing discourse on LLM biases and their implications for RAG-based system, offering insights that may inform the development of more robust and unbiased LLM systems.