 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs are Biased Evaluators But Not Biased for Retrieval Augmented Generation
Paper and Code
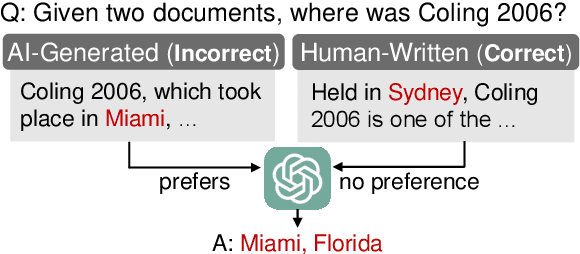
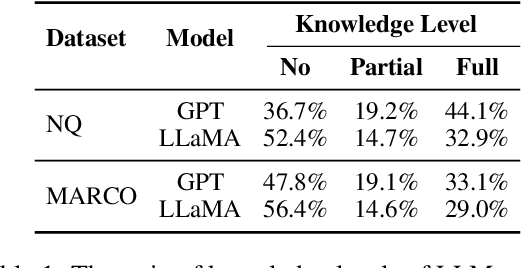
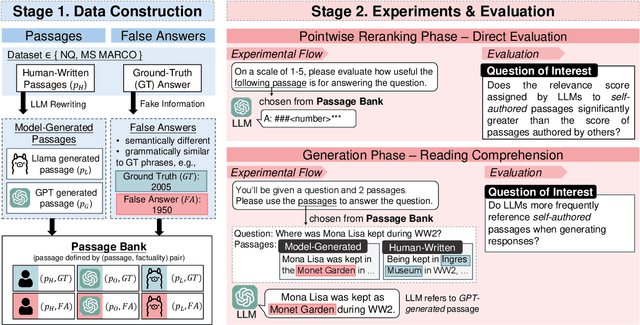

Recent studies have demonstrated that large language models (LLMs) exhibit significant biases in evaluation tasks, particularly in preferentially rating and favoring self-generated content. However, the extent to which this bias manifests in fact-oriented tasks, especially within retrieval-augmented generation (RAG) frameworks-where keyword extraction and factual accuracy take precedence over stylistic elements-remains unclear. Our study addresses this knowledge gap by simulating two critical phases of the RAG framework. In the first phase, we access the suitability of human-authored versus model-generated passages, emulating the pointwise reranking process. The second phase involves conducting pairwise reading comprehension tests to simulate the generation process. Contrary to previous findings indicating a self-preference in rating tasks, our results reveal no significant self-preference effect in RAG frameworks. Instead, we observe that factual accuracy significantly influences LLMs' output, even in the absence of prior knowledge. Our research contributes to the ongoing discourse on LLM biases and their implications for RAG-based system, offering insights that may inform the development of more robust and unbiased LLM systems.