 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenseNet and Support Vector Machine classifications of major depressive disorder using vertex-wise cortical features
Nov 18, 2023



Major depressive disorder (MDD) is a complex psychiatric disorder that affects the lives of hundreds of millions of individuals around the globe. Even today, researchers debate if morphological alterations in the brain are linked to MDD, likely due to the heterogeneity of this disorder. The application of deep learning tools to neuroimaging data, capable of capturing complex non-linear patterns, has the potential to provide diagnostic and predictive biomarkers for MDD. However, previous attempts to demarcate MDD patients and healthy controls (HC) based on segmented cortical features via linear machine learning approaches have reported low accuracies. In this study, we used globally representative data from the ENIGMA-MDD working group containing an extensive sample of people with MDD (N=2,772) and HC (N=4,240), which allows a comprehensive analysis with generalizable results. Based on the hypothesis that integration of vertex-wise cortical features can improve classification performance, we evaluated the classification of a DenseNet and a Support Vector Machine (SVM), with the expectation that the former would outperform the latter. As we analyzed a multi-site sample, we additionally applied the ComBat harmonization tool to remove potential nuisance effects of site. We found that both classifiers exhibited close to chance performance (balanced accuracy DenseNet: 51%; SVM: 53%), when estimated on unseen sites. Slightly higher classification performance (balanced accuracy DenseNet: 58%; SVM: 55%) was found when the cross-validation folds contained subjects from all sites, indicating site effect. In conclusion, the integration of vertex-wise morphometric features and the use of the non-linear classifier did not lead to the differentiability between MDD and HC. Our results support the notion that MDD classification on this combination of features and classifiers is unfeasible.
Multiple co-clustering based on nonparametric mixture models with heterogeneous marginal distributions
Oct 21, 2015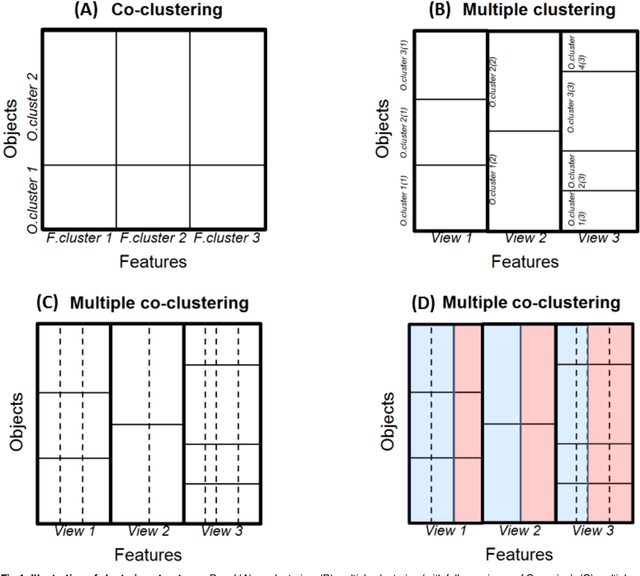

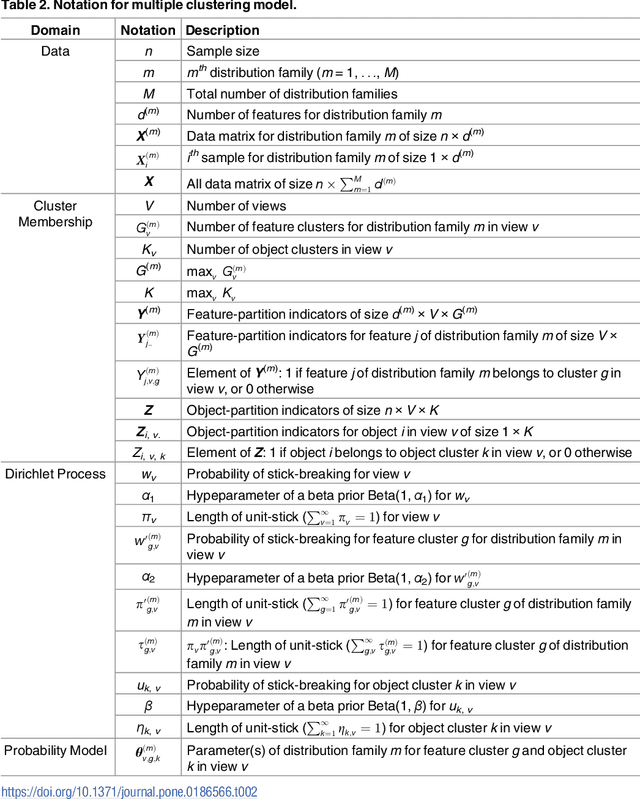
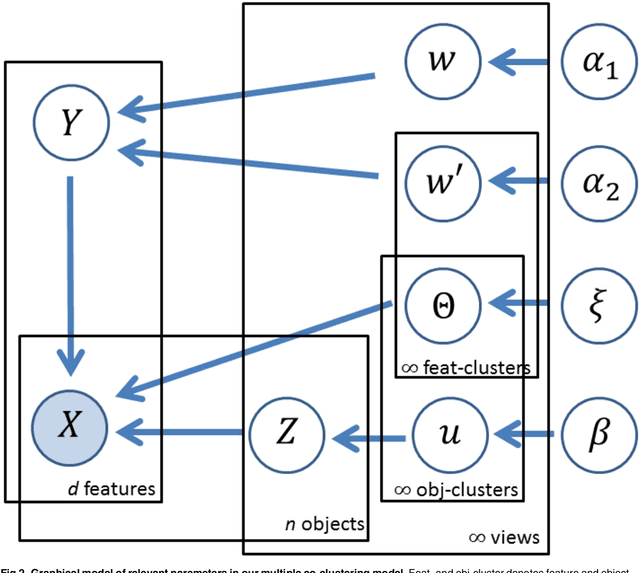
We propose a novel method for multiple clustering that assumes a co-clustering structure (partitions in both rows and columns of the data matrix) in each view. The new method is applicable to high-dimensional data. It is based on a nonparametric Bayesian approach in which the number of views and the number of feature-/subject clusters are inferred in a data-driven manner. We simultaneously model different distribution families, such as Gaussian, Poisson, and multinomial distributions in each cluster block. This makes our method applicable to datasets consisting of both numerical and categorical variables, which biomedical data typically do. Clustering solutions are based on variational inference with mean field approximation. We apply the proposed method to synthetic and real data, and show that our method outperforms other multiple clustering methods both in recovering true cluster structures and in computation time. Finally, we apply our method to a depression dataset with no true cluster structure available, from which useful inferences are drawn about possible clustering structures of the data.