 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple co-clustering based on nonparametric mixture models with heterogeneous marginal distributions
Oct 21, 2015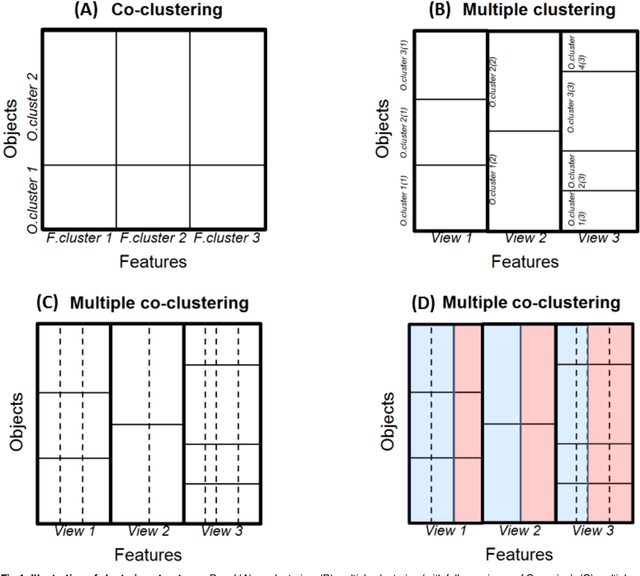

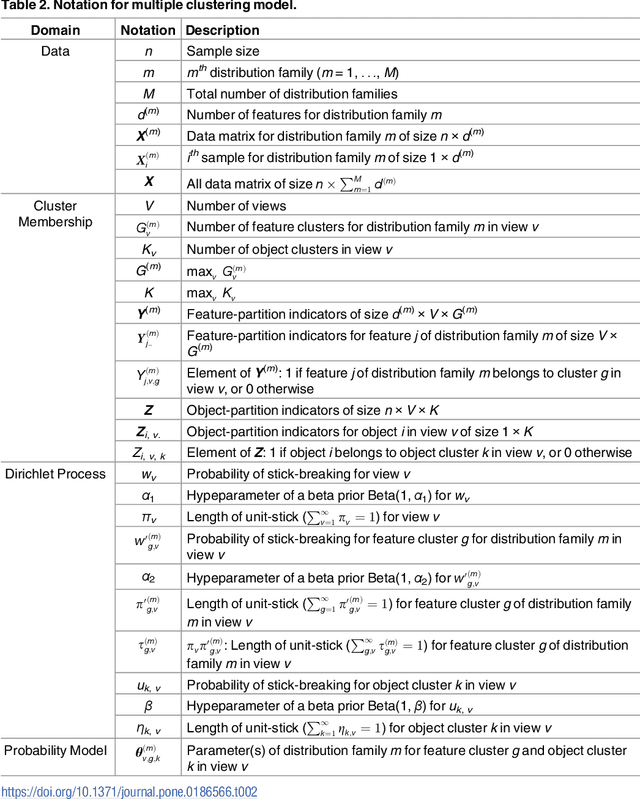
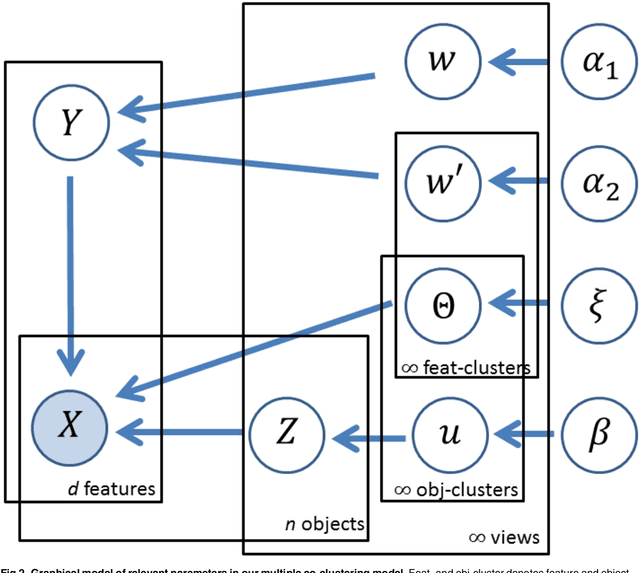
We propose a novel method for multiple clustering that assumes a co-clustering structure (partitions in both rows and columns of the data matrix) in each view. The new method is applicable to high-dimensional data. It is based on a nonparametric Bayesian approach in which the number of views and the number of feature-/subject clusters are inferred in a data-driven manner. We simultaneously model different distribution families, such as Gaussian, Poisson, and multinomial distributions in each cluster block. This makes our method applicable to datasets consisting of both numerical and categorical variables, which biomedical data typically do. Clustering solutions are based on variational inference with mean field approximation. We apply the proposed method to synthetic and real data, and show that our method outperforms other multiple clustering methods both in recovering true cluster structures and in computation time. Finally, we apply our method to a depression dataset with no true cluster structure available, from which useful inferences are drawn about possible clustering structures of the data.