 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSSAM:Code Search via Attention Matching of Code Semantics and Structures
Aug 08, 2022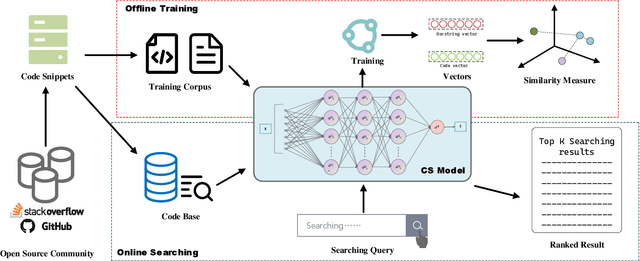
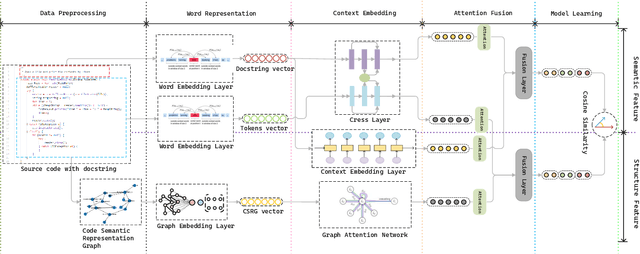
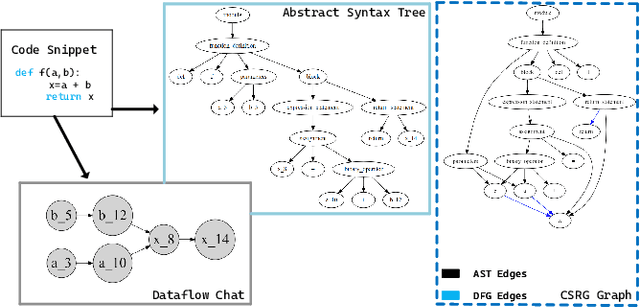
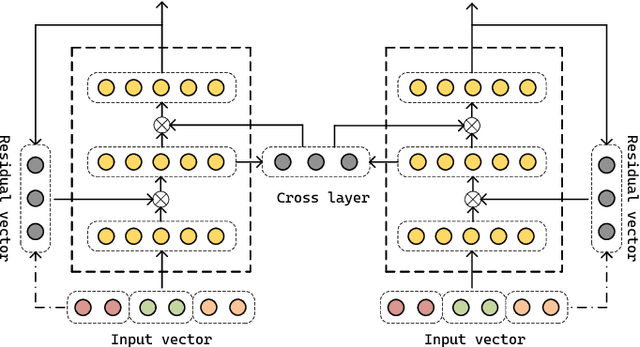
Despite the continuous efforts in improving both the effectiveness and efficiency of code search, two issues remained unsolved. First, programming languages have inherent strong structural linkages, and feature mining of code as text form would omit the structural information contained inside it. Second, there is a potential semantic relationship between code and query, it is challenging to align code and text across sequences so that vectors are spatially consistent during similarity matching. To tackle both issues, in this paper, a code search model named CSSAM (Code Semantics and Structures Attention Matching) is proposed. By introducing semantic and structural matching mechanisms, CSSAM effectively extracts and fuses multidimensional code features. Specifically, the cross and residual layer was developed to facilitate high-latitude spatial alignment of code and query at the token level. By leveraging the residual interaction, a matching module is designed to preserve more code semantics and descriptive features, that enhances the adhesion between the code and its corresponding query text. Besides, to improve the model's comprehension of the code's inherent structure, a code representation structure named CSRG (Code Semantic Representation Graph) is proposed for jointly representing abstract syntax tree nodes and the data flow of the codes. According to the experimental results on two publicly available datasets containing 540k and 330k code segments, CSSAM significantly outperforms the baselines in terms of achieving the highest SR@1/5/10, MRR, and NDCG@50 on both datasets respectively. Moreover, the ablation study is conducted to quantitatively measure the impact of each key component of CSSAM on the efficiency and effectiveness of code search, which offers the insights into the improvement of advanced code search solutions.