 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTake an Irregular Route: Enhance the Decoder of Time-Series Forecasting Transformer
Dec 10, 2023



With the development of Internet of Things (IoT) systems, precise long-term forecasting method is requisite for decision makers to evaluate current statuses and formulate future policies. Currently, Transformer and MLP are two paradigms for deep time-series forecasting and the former one is more prevailing in virtue of its exquisite attention mechanism and encoder-decoder architecture. However, data scientists seem to be more willing to dive into the research of encoder, leaving decoder unconcerned. Some researchers even adopt linear projections in lieu of the decoder to reduce the complexity. We argue that both extracting the features of input sequence and seeking the relations of input and prediction sequence, which are respective functions of encoder and decoder, are of paramount significance. Motivated from the success of FPN in CV field, we propose FPPformer to utilize bottom-up and top-down architectures respectively in encoder and decoder to build the full and rational hierarchy. The cutting-edge patch-wise attention is exploited and further developed with the combination, whose format is also different in encoder and decoder, of revamped element-wise attention in this work. Extensive experiments with six state-of-the-art baselines on twelve benchmarks verify the promising performances of FPPformer and the importance of elaborately devising decoder in time-series forecasting Transformer. The source code is released in https://github.com/OrigamiSL/FPPformer.
GBT: Two-stage transformer framework for non-stationary time series forecasting
Jul 17, 2023This paper shows that time series forecasting Transformer (TSFT) suffers from severe over-fitting problem caused by improper initialization method of unknown decoder inputs, esp. when handling non-stationary time series. Based on this observation, we propose GBT, a novel two-stage Transformer framework with Good Beginning. It decouples the prediction process of TSFT into two stages, including Auto-Regression stage and Self-Regression stage to tackle the problem of different statistical properties between input and prediction sequences.Prediction results of Auto-Regression stage serve as a Good Beginning, i.e., a better initialization for inputs of Self-Regression stage. We also propose Error Score Modification module to further enhance the forecasting capability of the Self-Regression stage in GBT. Extensive experiments on seven benchmark datasets demonstrate that GBT outperforms SOTA TSFTs (FEDformer, Pyraformer, ETSformer, etc.) and many other forecasting models (SCINet, N-HiTS, etc.) with only canonical attention and convolution while owning less time and space complexity. It is also general enough to couple with these models to strengthen their forecasting capability. The source code is available at: https://github.com/OrigamiSL/GBT
FDNet: Focal Decomposed Network for Efficient, Robust and Practical Time Series Forecasting
Jun 19, 2023
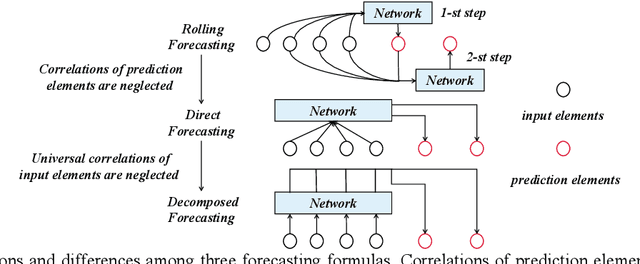
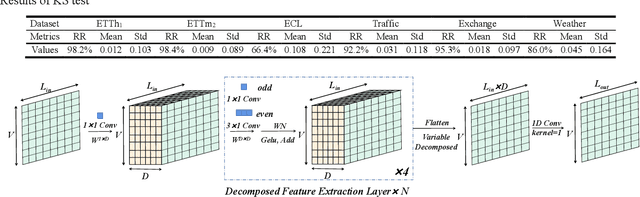
This paper presents FDNet: a Focal Decomposed Network for efficient, robust and practical time series forecasting. We break away from conventional deep time series forecasting formulas which obtain prediction results from universal feature maps of input sequences. In contrary, FDNet neglects universal correlations of input elements and only extracts fine-grained local features from input sequence. We show that: (1) Deep time series forecasting with only fine-grained local feature maps of input sequence is feasible upon theoretical basis. (2) By abandoning global coarse-grained feature maps, FDNet overcomes distribution shift problem caused by changing dynamics of time series which is common in real-world applications. (3) FDNet is not dependent on any inductive bias of time series except basic auto-regression, making it general and practical. Moreover, we propose focal input sequence decomposition method which decomposes input sequence in a focal manner for efficient and robust forecasting when facing Long Sequence Time series Input (LSTI) problem. FDNet achieves competitive forecasting performances on six real-world benchmarks and reduces prediction MSE by 38.4% on average compared with other thirteen SOTA baselines. The source code is available at https://github.com/OrigamiSL/FDNet.
Respecting Time Series Properties Makes Deep Time Series Forecasting Perfect
Jul 22, 2022
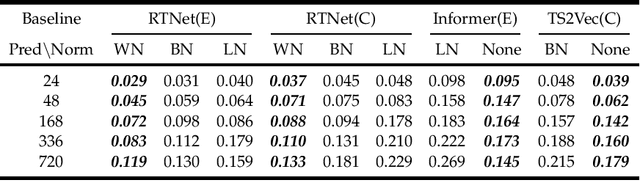
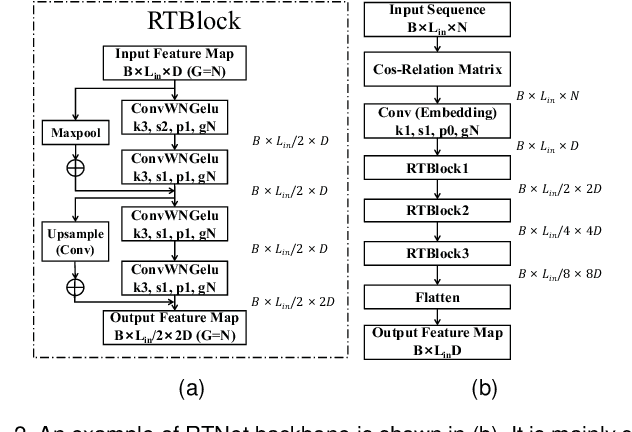

How to handle time features shall be the core question of any time series forecasting model. Ironically, it is often ignored or misunderstood by deep-learning based models, even those baselines which are state-of-the-art. This behavior makes their inefficient, untenable and unstable. In this paper, we rigorously analyze three prevalent but deficient/unfounded deep time series forecasting mechanisms or methods from the view of time series properties, including normalization methods, multivariate forecasting and input sequence length. Corresponding corollaries and solutions are given on both empirical and theoretical basis. We thereby propose a novel time series forecasting network, i.e. RTNet, on the basis of aforementioned analysis. It is general enough to be combined with both supervised and self-supervised forecasting format. Thanks to the core idea of respecting time series properties, no matter in which forecasting format, RTNet shows obviously superior forecasting performances compared with dozens of other SOTA time series forecasting baselines in three real-world benchmark datasets. By and large, it even occupies less time complexity and memory usage while acquiring better forecasting accuracy. The source code is available at https://github.com/OrigamiSL/RTNet.
TCCT: Tightly-Coupled Convolutional Transformer on Time Series Forecasting
Aug 29, 2021


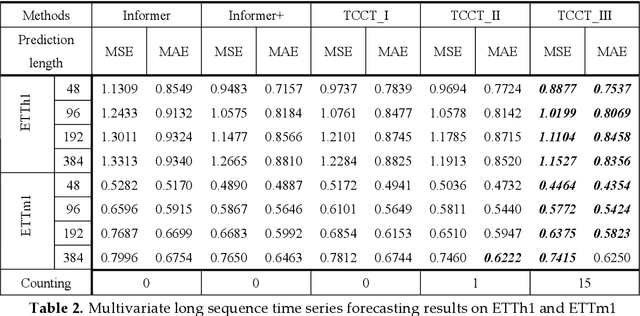
Time series forecasting is essential for a wide range of real-world applications. Recent studies have shown the superiority of Transformer in dealing with such problems, especially long sequence time series input(LSTI) and long sequence time series forecasting(LSTF) problems. To improve the efficiency and enhance the locality of Transformer, these studies combine Transformer with CNN in varying degrees. However, their combinations are loosely-coupled and do not make full use of CNN. To address this issue, we propose the concept of tightly-coupled convolutional Transformer(TCCT) and three TCCT architectures which apply transformed CNN architectures into Transformer: (1) CSPAttention: through fusing CSPNet with self-attention mechanism, the computation cost of self-attention mechanism is reduced by 30% and the memory usage is reduced by 50% while achieving equivalent or beyond prediction accuracy. (2) Dilated causal convolution: this method is to modify the distilling operation proposed by Informer through replacing canonical convolutional layers with dilated causal convolutional layers to gain exponentially receptive field growth. (3) Passthrough mechanism: the application of passthrough mechanism to stack of self-attention blocks helps Transformer-like models get more fine-grained information with negligible extra computation costs. Our experiments on real-world datasets show that our TCCT architectures could greatly improve the performance of existing state-of-art Transformer models on time series forecasting with much lower computation and memory costs, including canonical Transformer, LogTrans and Informer.