 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizing Few Data to Unseen Domains Flexibly Based on Label Smoothing Integrated with Distributionally Robust Optimization
Aug 09, 2024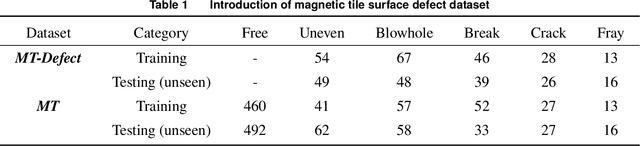



Overfitting commonly occurs when applying deep neural networks (DNNs) on small-scale datasets, where DNNs do not generalize well from existing data to unseen data. The main reason resulting in overfitting is that small-scale datasets cannot reflect the situations of the real world. Label smoothing (LS) is an effective regularization method to prevent overfitting, avoiding it by mixing one-hot labels with uniform label vectors. However, LS only focuses on labels while ignoring the distribution of existing data. In this paper, we introduce the distributionally robust optimization (DRO) to LS, achieving shift the existing data distribution flexibly to unseen domains when training DNNs. Specifically, we prove that the regularization of LS can be extended to a regularization term for the DNNs parameters when integrating DRO. The regularization term can be utilized to shift existing data to unseen domains and generate new data. Furthermore, we propose an approximate gradient-iteration label smoothing algorithm (GI-LS) to achieve the findings and train DNNs. We prove that the shift for the existing data does not influence the convergence of GI-LS. Since GI-LS incorporates a series of hyperparameters, we further consider using Bayesian optimization (BO) to find the relatively optimal combinations of these hyperparameters. Taking small-scale anomaly classification tasks as a case, we evaluate GI-LS, and the results clearly demonstrate its superior performance.