 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalytical Discovery of Manifold with Machine Learning
Apr 03, 2025


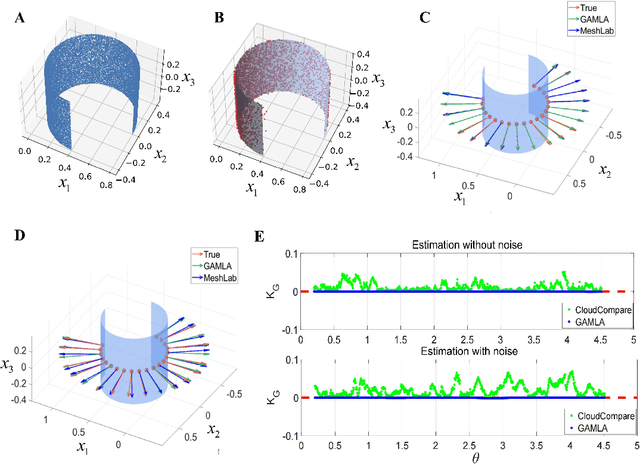
Understanding low-dimensional structures within high-dimensional data is crucial for visualization, interpretation, and denoising in complex datasets. Despite the advancements in manifold learning techniques, key challenges-such as limited global insight and the lack of interpretable analytical descriptions-remain unresolved. In this work, we introduce a novel framework, GAMLA (Global Analytical Manifold Learning using Auto-encoding). GAMLA employs a two-round training process within an auto-encoding framework to derive both character and complementary representations for the underlying manifold. With the character representation, the manifold is represented by a parametric function which unfold the manifold to provide a global coordinate. While with the complementary representation, an approximate explicit manifold description is developed, offering a global and analytical representation of smooth manifolds underlying high-dimensional datasets. This enables the analytical derivation of geometric properties such as curvature and normal vectors. Moreover, we find the two representations together decompose the whole latent space and can thus characterize the local spatial structure surrounding the manifold, proving particularly effective in anomaly detection and categorization. Through extensive experiments on benchmark datasets and real-world applications, GAMLA demonstrates its ability to achieve computational efficiency and interpretability while providing precise geometric and structural insights. This framework bridges the gap between data-driven manifold learning and analytical geometry, presenting a versatile tool for exploring the intrinsic properties of complex data sets.
The Importance of Suppressing Complete Reconstruction in Autoencoders for Unsupervised Outlier Detection
Nov 06, 2022



Autoencoders are widely used in outlier detection due to their superiority in handling high-dimensional and nonlinear datasets. The reconstruction of any dataset by the autoencoder can be considered as a complex regression process. In regression analysis, outliers can usually be divided into high leverage points and influential points. Although the autoencoder has shown good results for the identification of influential points, there are still some problems when detect high leverage points. Through theoretical derivation, we found that most outliers are detected in the direction corresponding to the worst-recovered principal component, but in the direction of the well-recovered principal components, the anomalies are often ignored. We propose a new loss function which solve the above deficiencies in outlier detection. The core idea of our scheme is that in order to better detect high leverage points, we should suppress the complete reconstruction of the dataset to convert high leverage points into influential points, and it is also necessary to ensure that the differences between the eigenvalues of the covariance matrix of the original dataset and their corresponding reconstructed results in the direction of each principal component are equal. Besides, we explain the rationality of our scheme through rigorous theoretical derivation. Finally, our experiments on multiple datasets confirm that our scheme significantly improves the accuracy of outlier detection.