 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Parameter-free Affinity Based Clustering
Jan 11, 2016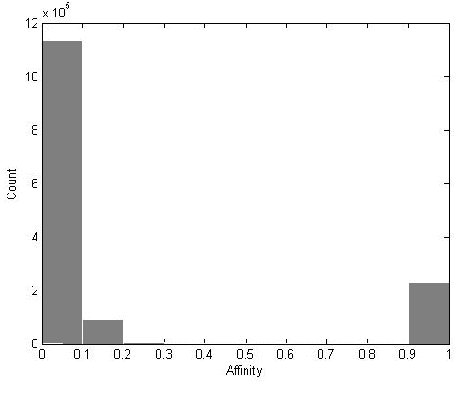

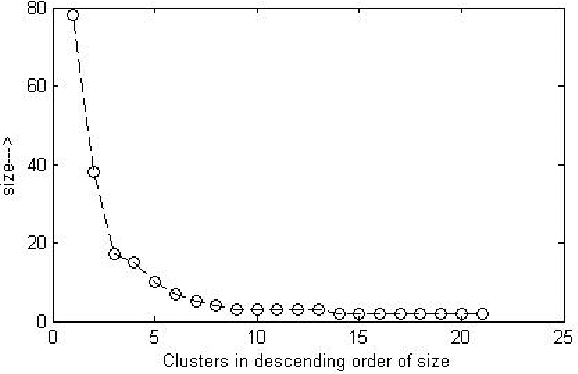

Several methods have been proposed to estimate the number of clusters in a dataset; the basic ideal behind all of them has been to study an index that measures inter-cluster separation and intra-cluster cohesion over a range of cluster numbers and report the number which gives an optimum value of the index. In this paper we propose a simple, parameter free approach that is like human cognition to form clusters, where closely lying points are easily identified to form a cluster and total number of clusters are revealed. To identify closely lying points, affinity of two points is defined as a function of distance and a threshold affinity is identified, above which two points in a dataset are likely to be in the same cluster. Well separated clusters are identified even in the presence of outliers, whereas for not so well separated dataset, final number of clusters are estimated and the detected clusters are merged to produce the final clusters. Experiments performed with several large dimensional synthetic and real datasets show good results with robustness to noise and density variation within dataset.