 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrban Region Profiling via A Multi-Graph Representation Learning Framework
Feb 04, 2022

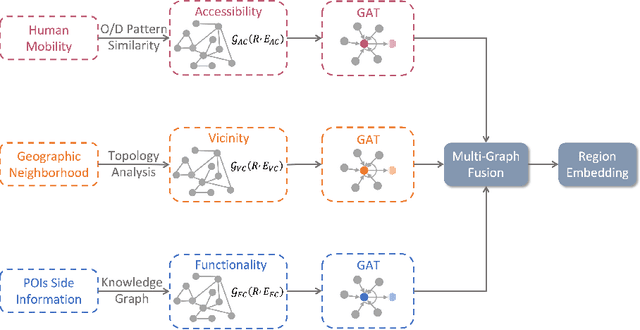

Urban region profiling can benefit urban analytics. Although existing studies have made great efforts to learn urban region representation from multi-source urban data, there are still three limitations: (1) Most related methods focused merely on global-level inter-region relations while overlooking local-level geographical contextual signals and intra-region information; (2) Most previous works failed to develop an effective yet integrated fusion module which can deeply fuse multi-graph correlations; (3) State-of-the-art methods do not perform well in regions with high variance socioeconomic attributes. To address these challenges, we propose a multi-graph representative learning framework, called Region2Vec, for urban region profiling. Specifically, except that human mobility is encoded for inter-region relations, geographic neighborhood is introduced for capturing geographical contextual information while POI side information is adopted for representing intra-region information by knowledge graph. Then, graphs are used to capture accessibility, vicinity, and functionality correlations among regions. To consider the discriminative properties of multiple graphs, an encoder-decoder multi-graph fusion module is further proposed to jointly learn comprehensive representations. Experiments on real-world datasets show that Region2Vec can be employed in three applications and outperforms all state-of-the-art baselines. Particularly, Region2Vec has better performance than previous studies in regions with high variance socioeconomic attributes.
Efficient video annotation with visual interpolation and frame selection guidance
Dec 23, 2020



We introduce a unified framework for generic video annotation with bounding boxes. Video annotation is a longstanding problem, as it is a tedious and time-consuming process. We tackle two important challenges of video annotation: (1) automatic temporal interpolation and extrapolation of bounding boxes provided by a human annotator on a subset of all frames, and (2) automatic selection of frames to annotate manually. Our contribution is two-fold: first, we propose a model that has both interpolating and extrapolating capabilities; second, we propose a guiding mechanism that sequentially generates suggestions for what frame to annotate next, based on the annotations made previously. We extensively evaluate our approach on several challenging datasets in simulation and demonstrate a reduction in terms of the number of manual bounding boxes drawn by 60% over linear interpolation and by 35% over an off-the-shelf tracker. Moreover, we also show 10% annotation time improvement over a state-of-the-art method for video annotation with bounding boxes [25]. Finally, we run human annotation experiments and provide extensive analysis of the results, showing that our approach reduces actual measured annotation time by 50% compared to commonly used linear interpolation.