 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Physical Layer Authentication for Mobile Scenarios Using a Synthetic Dataset Enhanced Deep Learning Approach
Aug 28, 2025The Internet of Things (IoT) is ubiquitous thanks to the rapid development of wireless technologies. However, the broadcast nature of wireless transmissions results in great vulnerability to device authentication. Physical layer authentication emerges as a promising approach by exploiting the unique channel characteristics. However, a practical scheme applicable to dynamic channel variations is still missing. In this paper, we proposed a deep learning-based physical layer channel state information (CSI) authentication for mobile scenarios and carried out comprehensive simulation and experimental evaluation using IEEE 802.11n. Specifically, a synthetic training dataset was generated based on the WLAN TGn channel model and the autocorrelation and the distance correlation of the channel, which can significantly reduce the overhead of manually collecting experimental datasets. A convolutional neural network (CNN)-based Siamese network was exploited to learn the temporal and spatial correlation between the CSI pair and output a score to measure their similarity. We adopted a synergistic methodology involving both simulation and experimental evaluation. The experimental testbed consisted of WiFi IoT development kits and a few typical scenarios were specifically considered. Both simulation and experimental evaluation demonstrated excellent generalization performance of our proposed deep learning-based approach and excellent authentication performance. Demonstrated by our practical measurement results, our proposed scheme improved the area under the curve (AUC) by 0.03 compared to the fully connected network-based (FCN-based) Siamese model and by 0.06 compared to the correlation-based benchmark algorithm.
Compressed Sensor Caching and Collaborative Sparse Data Recovery with Anchor Alignment
Jun 14, 2024This work examines the compressed sensor caching problem in wireless sensor networks and devises efficient distributed sparse data recovery algorithms to enable collaboration among multiple caches. In this problem, each cache is only allowed to access measurements from a small subset of sensors within its vicinity to reduce both cache size and data acquisition overhead. To enable reliable data recovery with limited access to measurements, we propose a distributed sparse data recovery method, called the collaborative sparse recovery by anchor alignment (CoSR-AA) algorithm, where collaboration among caches is enabled by aligning their locally recovered data at a few anchor nodes. The proposed algorithm is based on the consensus alternating direction method of multipliers (ADMM) algorithm but with message exchange that is reduced by considering the proposed anchor alignment strategy. Then, by the deep unfolding of the ADMM iterations, we further propose the Deep CoSR-AA algorithm that can be used to significantly reduce the number of iterations. We obtain a graph neural network architecture where message exchange is done more efficiently by an embedded autoencoder. Simulations are provided to demonstrate the effectiveness of the proposed collaborative recovery algorithms in terms of the improved reconstruction quality and the reduced communication overhead due to anchor alignment.
A Mathematical Theory for Learning Semantic Languages by Abstract Learners
Apr 13, 2024Recent advances in Large Language Models (LLMs) have demonstrated the emergence of capabilities (learned skills) when the number of system parameters and the size of training data surpass certain thresholds. The exact mechanisms behind such phenomena are not fully understood and remain a topic of active research. Inspired by the skill-text bipartite graph model presented in [1] for modeling semantic language, we develop a mathematical theory to explain the emergence of learned skills, taking the learning (or training) process into account. Our approach models the learning process for skills in the skill-text bipartite graph as an iterative decoding process in Low-Density Parity Check (LDPC) codes and Irregular Repetition Slotted ALOHA (IRSA). Using density evolution analysis, we demonstrate the emergence of learned skills when the ratio of the size of training texts to the number of skills exceeds a certain threshold. Our analysis also yields a scaling law for testing errors relative to the size of training texts. Upon completion of the training, we propose a method for semantic compression and discuss its application in semantic communication.
An Attribute-Aligned Strategy for Learning Speech Representation
Jun 05, 2021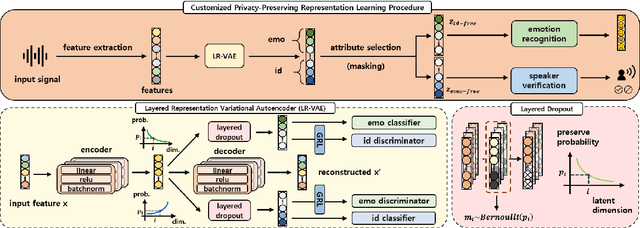
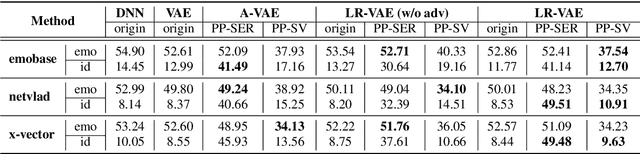
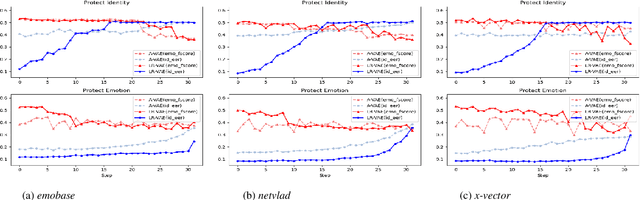
Advancement in speech technology has brought convenience to our life. However, the concern is on the rise as speech signal contains multiple personal attributes, which would lead to either sensitive information leakage or bias toward decision. In this work, we propose an attribute-aligned learning strategy to derive speech representation that can flexibly address these issues by attribute-selection mechanism. Specifically, we propose a layered-representation variational autoencoder (LR-VAE), which factorizes speech representation into attribute-sensitive nodes, to derive an identity-free representation for speech emotion recognition (SER), and an emotionless representation for speaker verification (SV). Our proposed method achieves competitive performances on identity-free SER and a better performance on emotionless SV, comparing to the current state-of-the-art method of using adversarial learning applied on a large emotion corpora, the MSP-Podcast. Also, our proposed learning strategy reduces the model and training process needed to achieve multiple privacy-preserving tasks.