 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGEM: stochastic gradient with energy and momentum
Aug 03, 2022
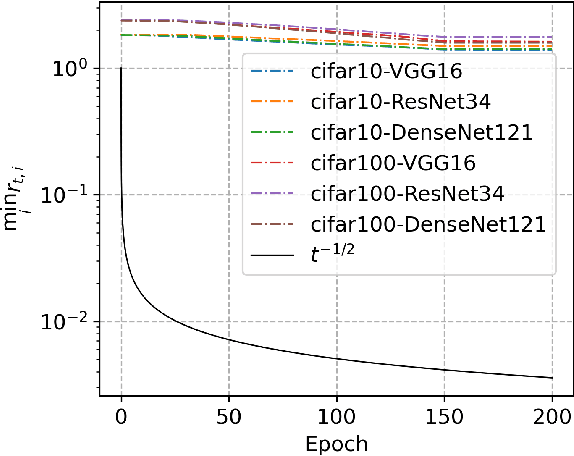

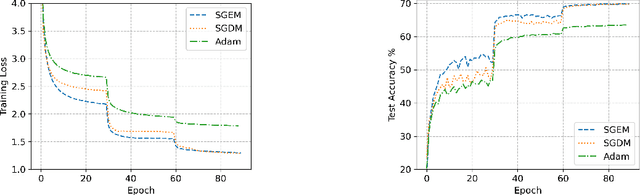
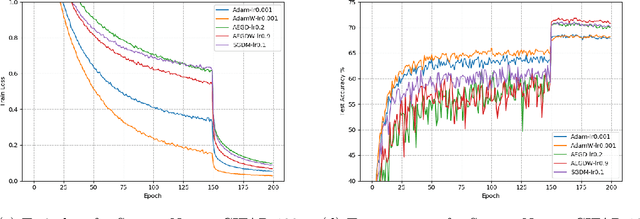
In this paper, we propose SGEM, Stochastic Gradient with Energy and Momentum, to solve a large class of general non-convex stochastic optimization problems, based on the AEGD method that originated in the work [AEGD: Adaptive Gradient Descent with Energy. arXiv: 2010.05109]. SGEM incorporates both energy and momentum at the same time so as to inherit their dual advantages. We show that SGEM features an unconditional energy stability property, and derive energy-dependent convergence rates in the general nonconvex stochastic setting, as well as a regret bound in the online convex setting. A lower threshold for the energy variable is also provided. Our experimental results show that SGEM converges faster than AEGD and generalizes better or at least as well as SGDM in training some deep neural networks.
An Adaptive Gradient Method with Energy and Momentum
Mar 23, 2022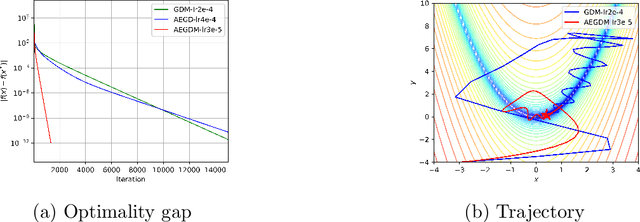
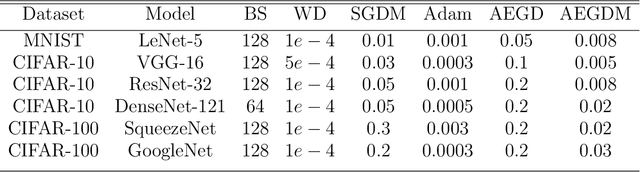
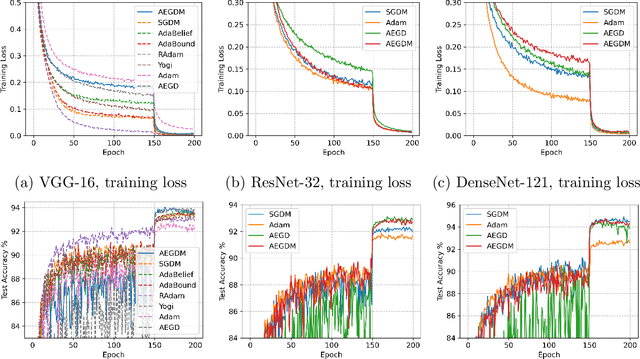

We introduce a novel algorithm for gradient-based optimization of stochastic objective functions. The method may be seen as a variant of SGD with momentum equipped with an adaptive learning rate automatically adjusted by an 'energy' variable. The method is simple to implement, computationally efficient, and well suited for large-scale machine learning problems. The method exhibits unconditional energy stability for any size of the base learning rate. We provide a regret bound on the convergence rate under the online convex optimization framework. We also establish the energy-dependent convergence rate of the algorithm to a stationary point in the stochastic non-convex setting. In addition, a sufficient condition is provided to guarantee a positive lower threshold for the energy variable. Our experiments demonstrate that the algorithm converges fast while generalizing better than or as well as SGD with momentum in training deep neural networks, and compares also favorably to Adam.
* 29 pages, 6 figures
AEGD: Adaptive Gradient Decent with Energy
Oct 10, 2020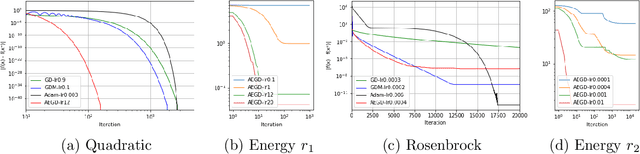
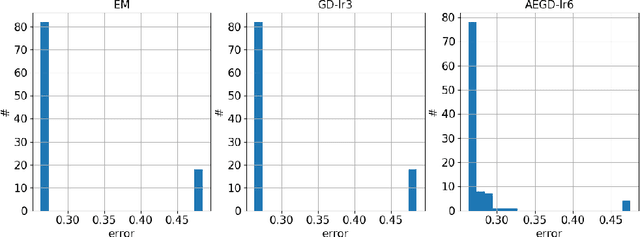
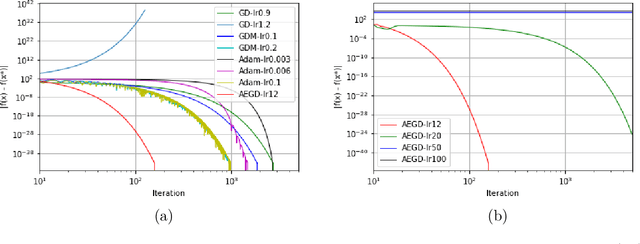
In this paper, we propose AEGD, a new algorithm for first-order gradient-based optimization of stochastic objective functions, based on adaptive updates of quadratic energy. As long as an objective function is bounded from below, AEGD can be applied, and it is shown to be unconditionally energy stable, irrespective of the step size. In addition, AEGD enjoys tight convergence rates, yet allows a large step size. The method is straightforward to implement and requires little tuning of hyper-parameters. Experimental results demonstrate that AEGD works well for various optimization problems: it is robust with respect to initial data, capable of making rapid initial progress, shows comparable and most times better generalization performance than SGD with momentum for deep neural networks. The implementation of the algorithm can be found at https://github.com/txping/AEGD.