 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Model Is Superior LLM-Judge, Yet Suffers from Biases
Jan 07, 2026This paper presents the first systematic comparison investigating whether Large Reasoning Models (LRMs) are superior judge to non-reasoning LLMs. Our empirical analysis yields four key findings: 1) LRMs outperform non-reasoning LLMs in terms of judgment accuracy, particularly on reasoning-intensive tasks; 2) LRMs demonstrate superior instruction-following capabilities in evaluation contexts; 3) LRMs exhibit enhanced robustness against adversarial attacks targeting judgment tasks; 4) However, LRMs still exhibit strong biases in superficial quality. To improve the robustness against biases, we propose PlanJudge, an evaluation strategy that prompts the model to generate an explicit evaluation plan before execution. Despite its simplicity, our experiments demonstrate that PlanJudge significantly mitigates biases in both LRMs and standard LLMs.
An In-depth Evaluation of GPT-4 in Sentence Simplification with Error-based Human Assessment
Mar 08, 2024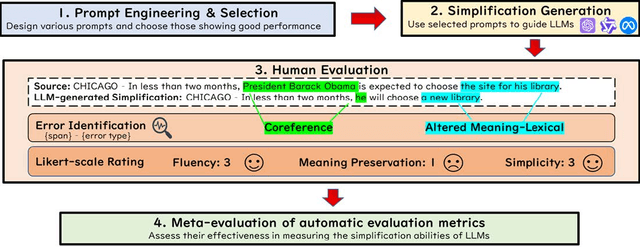

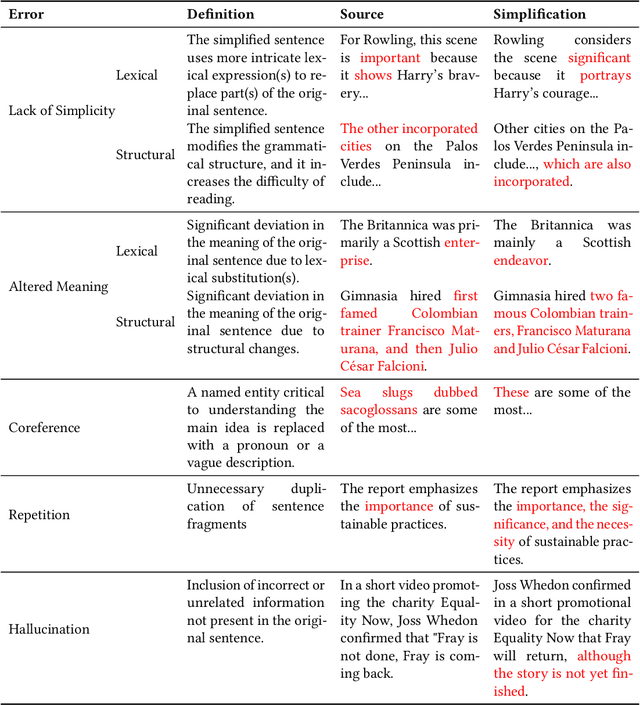
Sentence simplification, which rewrites a sentence to be easier to read and understand, is a promising technique to help people with various reading difficulties. With the rise of advanced large language models (LLMs), evaluating their performance in sentence simplification has become imperative. Recent studies have used both automatic metrics and human evaluations to assess the simplification abilities of LLMs. However, the suitability of existing evaluation methodologies for LLMs remains in question. First, the suitability of current automatic metrics on LLMs' simplification evaluation is still uncertain. Second, current human evaluation approaches in sentence simplification often fall into two extremes: they are either too superficial, failing to offer a clear understanding of the models' performance, or overly detailed, making the annotation process complex and prone to inconsistency, which in turn affects the evaluation's reliability. To address these problems, this study provides in-depth insights into LLMs' performance while ensuring the reliability of the evaluation. We design an error-based human annotation framework to assess the GPT-4's simplification capabilities. Results show that GPT-4 generally generates fewer erroneous simplification outputs compared to the current state-of-the-art. However, LLMs have their limitations, as seen in GPT-4's struggles with lexical paraphrasing. Furthermore, we conduct meta-evaluations on widely used automatic metrics using our human annotations. We find that while these metrics are effective for significant quality differences, they lack sufficient sensitivity to assess the overall high-quality simplification by GPT-4.