 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Time Series Forecasting With Shared Attention
Jan 24, 2021
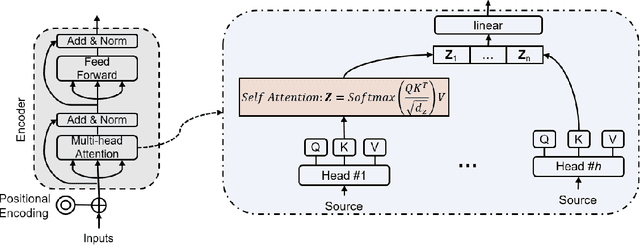
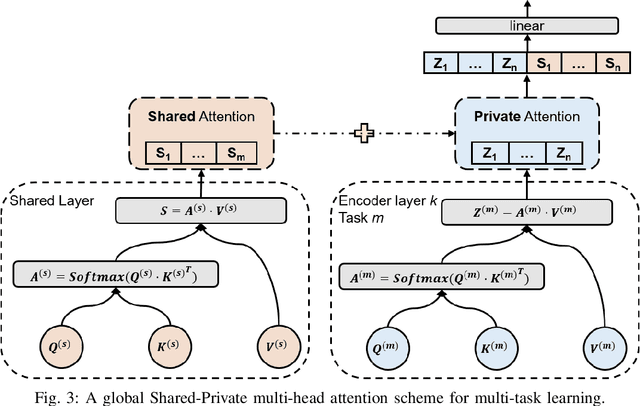
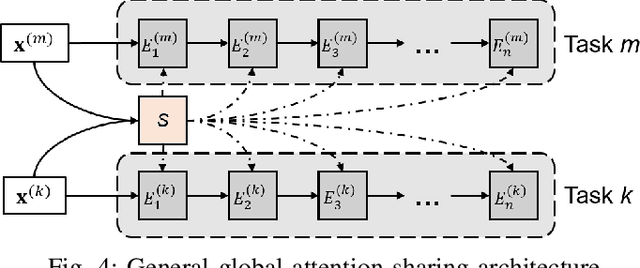
Time series forecasting is a key component in many industrial and business decision processes and recurrent neural network (RNN) based models have achieved impressive progress on various time series forecasting tasks. However, most of the existing methods focus on single-task forecasting problems by learning separately based on limited supervised objectives, which often suffer from insufficient training instances. As the Transformer architecture and other attention-based models have demonstrated its great capability of capturing long term dependency, we propose two self-attention based sharing schemes for multi-task time series forecasting which can train jointly across multiple tasks. We augment a sequence of paralleled Transformer encoders with an external public multi-head attention function, which is updated by all data of all tasks. Experiments on a number of real-world multi-task time series forecasting tasks show that our proposed architectures can not only outperform the state-of-the-art single-task forecasting baselines but also outperform the RNN-based multi-task forecasting method.