 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Agent: A Holistic Architecture for Orchestrating Data+AI Ecosystems
Jul 02, 2025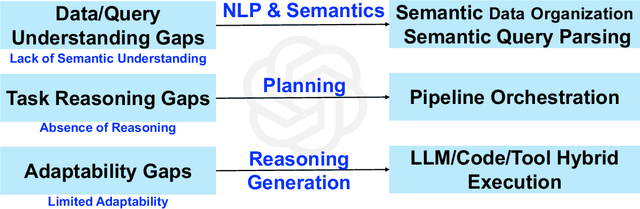

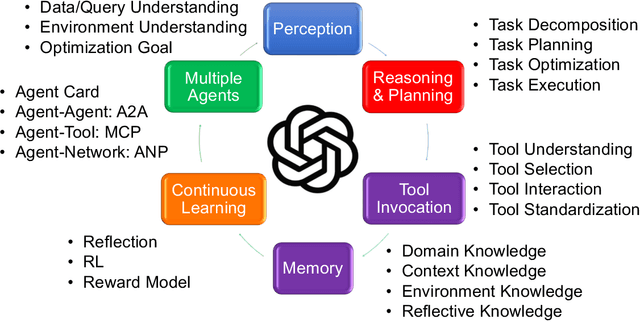
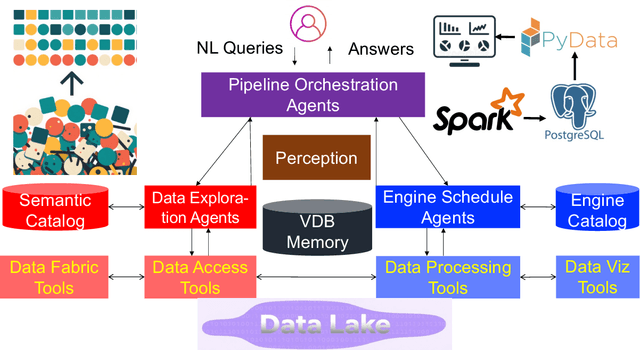
Traditional Data+AI systems utilize data-driven techniques to optimize performance, but they rely heavily on human experts to orchestrate system pipelines, enabling them to adapt to changes in data, queries, tasks, and environments. For instance, while there are numerous data science tools available, developing a pipeline planning system to coordinate these tools remains challenging. This difficulty arises because existing Data+AI systems have limited capabilities in semantic understanding, reasoning, and planning. Fortunately, we have witnessed the success of large language models (LLMs) in enhancing semantic understanding, reasoning, and planning abilities. It is crucial to incorporate LLM techniques to revolutionize data systems for orchestrating Data+AI applications effectively. To achieve this, we propose the concept of a 'Data Agent' - a comprehensive architecture designed to orchestrate Data+AI ecosystems, which focuses on tackling data-related tasks by integrating knowledge comprehension, reasoning, and planning capabilities. We delve into the challenges involved in designing data agents, such as understanding data/queries/environments/tools, orchestrating pipelines/workflows, optimizing and executing pipelines, and fostering pipeline self-reflection. Furthermore, we present examples of data agent systems, including a data science agent, data analytics agents (such as unstructured data analytics agent, semantic structured data analytics agent, data lake analytics agent, and multi-modal data analytics agent), and a database administrator (DBA) agent. We also outline several open challenges associated with designing data agent systems.
LLM-Enhanced Data Management
Feb 04, 2024Machine learning (ML) techniques for optimizing data management problems have been extensively studied and widely deployed in recent five years. However traditional ML methods have limitations on generalizability (adapting to different scenarios) and inference ability (understanding the context). Fortunately, large language models (LLMs) have shown high generalizability and human-competitive abilities in understanding context, which are promising for data management tasks (e.g., database diagnosis, database tuning). However, existing LLMs have several limitations: hallucination, high cost, and low accuracy for complicated tasks. To address these challenges, we design LLMDB, an LLM-enhanced data management paradigm which has generalizability and high inference ability while avoiding hallucination, reducing LLM cost, and achieving high accuracy. LLMDB embeds domain-specific knowledge to avoid hallucination by LLM fine-tuning and prompt engineering. LLMDB reduces the high cost of LLMs by vector databases which provide semantic search and caching abilities. LLMDB improves the task accuracy by LLM agent which provides multiple-round inference and pipeline executions. We showcase three real-world scenarios that LLMDB can well support, including query rewrite, database diagnosis and data analytics. We also summarize the open research challenges of LLMDB.