 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning for Bayesian Optimization on Heterogeneous Search Spaces
Sep 28, 2023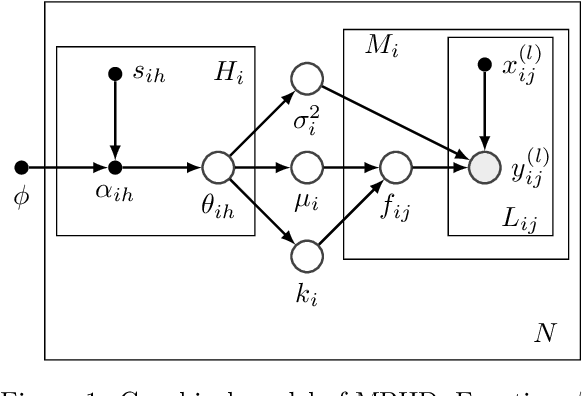

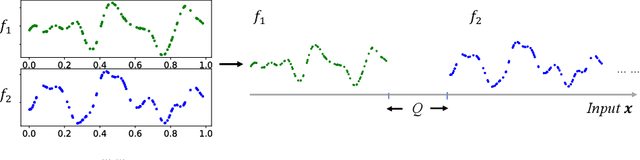
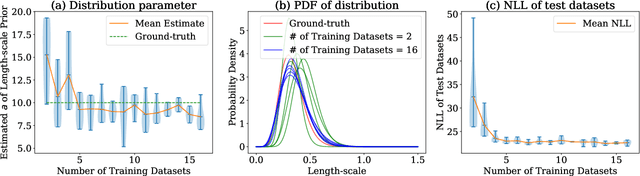
Bayesian optimization (BO) is a popular black-box function optimization method, which makes sequential decisions based on a Bayesian model, typically a Gaussian process (GP), of the function. To ensure the quality of the model, transfer learning approaches have been developed to automatically design GP priors by learning from observations on "training" functions. These training functions are typically required to have the same domain as the "test" function (black-box function to be optimized). In this paper, we introduce MPHD, a model pre-training method on heterogeneous domains, which uses a neural net mapping from domain-specific contexts to specifications of hierarchical GPs. MPHD can be seamlessly integrated with BO to transfer knowledge across heterogeneous search spaces. Our theoretical and empirical results demonstrate the validity of MPHD and its superior performance on challenging black-box function optimization tasks.
HyperBO+: Pre-training a universal prior for Bayesian optimization with hierarchical Gaussian processes
Dec 20, 2022



Bayesian optimization (BO), while proved highly effective for many black-box function optimization tasks, requires practitioners to carefully select priors that well model their functions of interest. Rather than specifying by hand, researchers have investigated transfer learning based methods to automatically learn the priors, e.g. multi-task BO (Swersky et al., 2013), few-shot BO (Wistuba and Grabocka, 2021) and HyperBO (Wang et al., 2022). However, those prior learning methods typically assume that the input domains are the same for all tasks, weakening their ability to use observations on functions with different domains or generalize the learned priors to BO on different search spaces. In this work, we present HyperBO+: a pre-training approach for hierarchical Gaussian processes that enables the same prior to work universally for Bayesian optimization on functions with different domains. We propose a two-step pre-training method and analyze its appealing asymptotic properties and benefits to BO both theoretically and empirically. On real-world hyperparameter tuning tasks that involve multiple search spaces, we demonstrate that HyperBO+ is able to generalize to unseen search spaces and achieves lower regrets than competitive baselines.