 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAMVI-2: A Visual Tool for Comparing and Tuning Word Embedding Models
Oct 22, 2018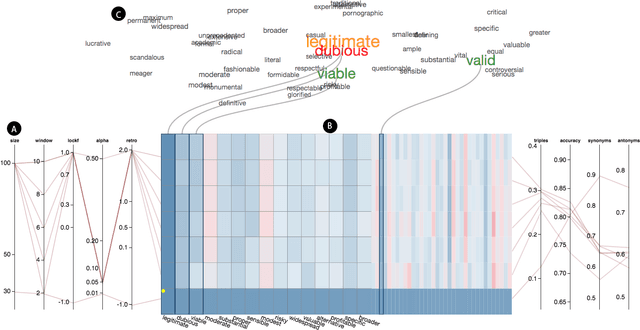
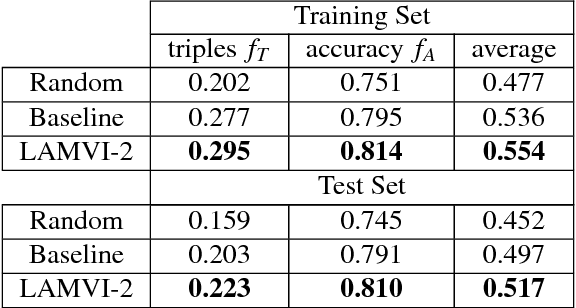
Tuning machine learning models, particularly deep learning architectures, is a complex process. Automated hyperparameter tuning algorithms often depend on specific optimization metrics. However, in many situations, a developer trades one metric against another: accuracy versus overfitting, precision versus recall, smaller models and accuracy, etc. With deep learning, not only are the model's representations opaque, the model's behavior when parameters "knobs" are changed may also be unpredictable. Thus, picking the "best" model often requires time-consuming model comparison. In this work, we introduce LAMVI-2, a visual analytics system to support a developer in comparing hyperparameter settings and outcomes. By focusing on word-embedding models ("deep learning for text") we integrate views to compare both high-level statistics as well as internal model behaviors (e.g., comparing word 'distances'). We demonstrate how developers can work with LAMVI-2 to more quickly and accurately narrow down an appropriate and effective application-specific model.
word2vec Parameter Learning Explained
Jun 05, 2016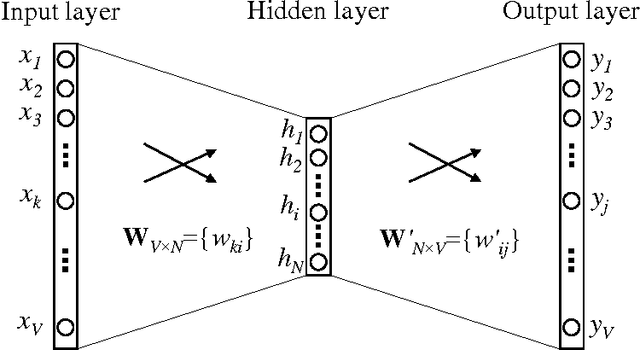
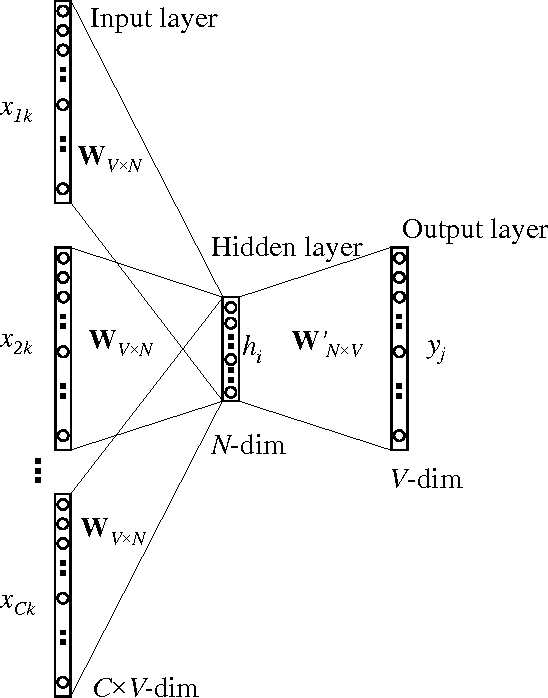
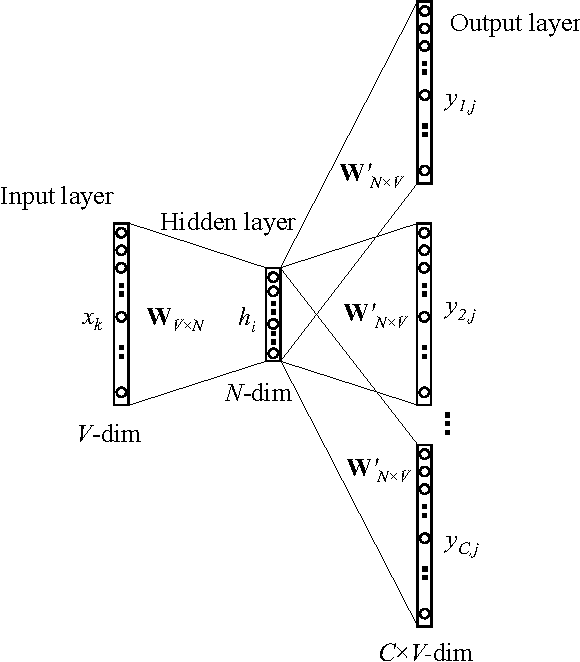
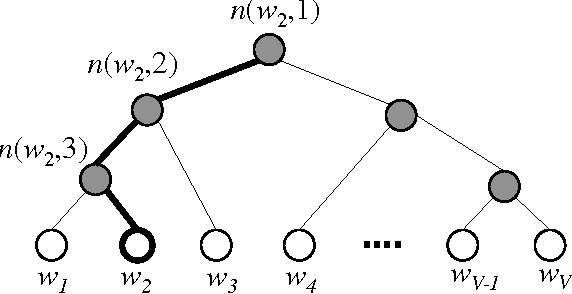
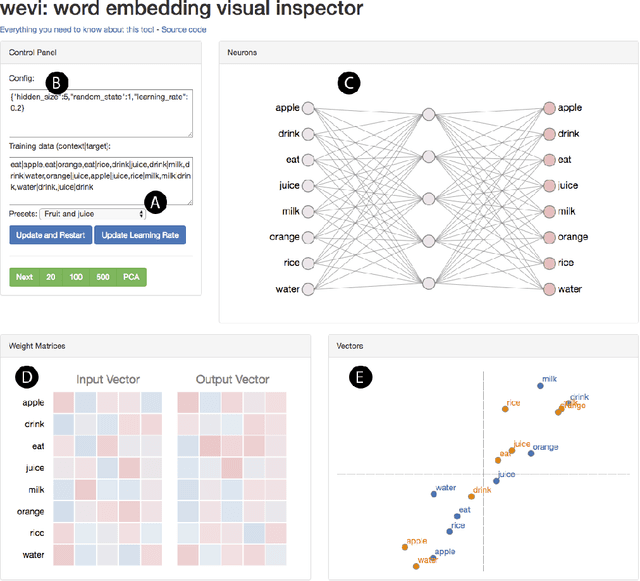
The word2vec model and application by Mikolov et al. have attracted a great amount of attention in recent two years. The vector representations of words learned by word2vec models have been shown to carry semantic meanings and are useful in various NLP tasks. As an increasing number of researchers would like to experiment with word2vec or similar techniques, I notice that there lacks a material that comprehensively explains the parameter learning process of word embedding models in details, thus preventing researchers that are non-experts in neural networks from understanding the working mechanism of such models. This note provides detailed derivations and explanations of the parameter update equations of the word2vec models, including the original continuous bag-of-word (CBOW) and skip-gram (SG) models, as well as advanced optimization techniques, including hierarchical softmax and negative sampling. Intuitive interpretations of the gradient equations are also provided alongside mathematical derivations. In the appendix, a review on the basics of neuron networks and backpropagation is provided. I also created an interactive demo, wevi, to facilitate the intuitive understanding of the model.
Introduction to the iDian
Oct 15, 2010
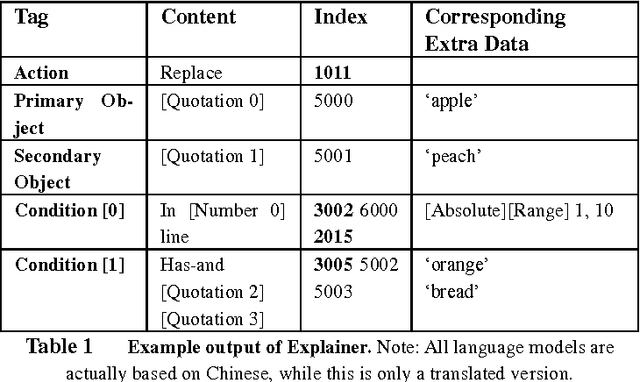
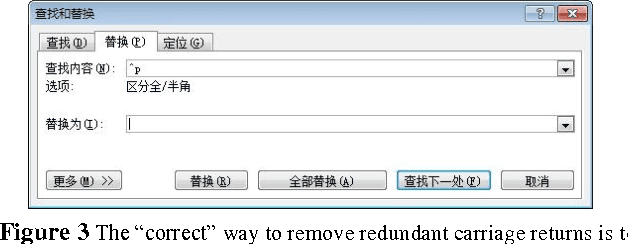
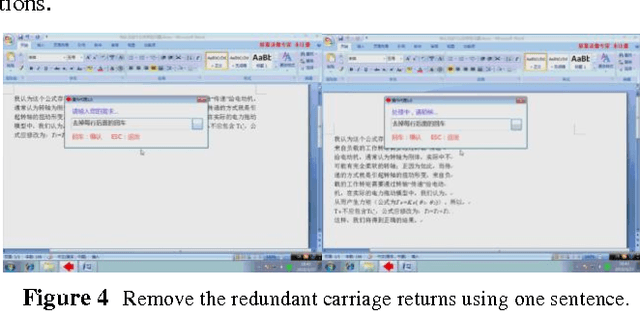
The iDian (previously named as the Operation Agent System) is a framework designed to enable computer users to operate software in natural language. Distinct from current speech-recognition systems, our solution supports format-free combinations of orders, and is open to both developers and customers. We used a multi-layer structure to build the entire framework, approached rule-based natural language processing, and implemented demos narrowing down to Windows, text-editing and a few other applications. This essay will firstly give an overview of the entire system, and then scrutinize the functions and structure of the system, and finally discuss the prospective de-velopment, esp. on-line interaction functions.