 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPBA: Utilizing Speech Large Language Model for Backdoor Attacks on Speech Classification Models
Jun 10, 2025Deep speech classification tasks, including keyword spotting and speaker verification, are vital in speech-based human-computer interaction. Recently, the security of these technologies has been revealed to be susceptible to backdoor attacks. Specifically, attackers use noisy disruption triggers and speech element triggers to produce poisoned speech samples that train models to become vulnerable. However, these methods typically create only a limited number of backdoors due to the inherent constraints of the trigger function. In this paper, we propose that speech backdoor attacks can strategically focus on speech elements such as timbre and emotion, leveraging the Speech Large Language Model (SLLM) to generate diverse triggers. Increasing the number of triggers may disproportionately elevate the poisoning rate, resulting in higher attack costs and a lower success rate per trigger. We introduce the Multiple Gradient Descent Algorithm (MGDA) as a mitigation strategy to address this challenge. The proposed attack is called the Speech Prompt Backdoor Attack (SPBA). Building on this foundation, we conducted attack experiments on two speech classification tasks, demonstrating that SPBA shows significant trigger effectiveness and achieves exceptional performance in attack metrics.
Pureformer-VC: Non-parallel Voice Conversion with Pure Stylized Transformer Blocks and Triplet Discriminative Training
Jun 10, 2025As a foundational technology for intelligent human-computer interaction, voice conversion (VC) seeks to transform speech from any source timbre into any target timbre. Traditional voice conversion methods based on Generative Adversarial Networks (GANs) encounter significant challenges in precisely encoding diverse speech elements and effectively synthesising these elements into natural-sounding converted speech. To overcome these limitations, we introduce Pureformer-VC, an encoder-decoder framework that utilizes Conformer blocks to build a disentangled encoder and employs Zipformer blocks to create a style transfer decoder. We adopt a variational decoupled training approach to isolate speech components using a Variational Autoencoder (VAE), complemented by triplet discriminative training to enhance the speaker's discriminative capabilities. Furthermore, we incorporate the Attention Style Transfer Mechanism (ASTM) with Zipformer's shared weights to improve the style transfer performance in the decoder. We conducted experiments on two multi-speaker datasets. The experimental results demonstrate that the proposed model achieves comparable subjective evaluation scores while significantly enhancing objective metrics compared to existing approaches in many-to-many and many-to-one VC scenarios.
Pureformer-VC: Non-parallel One-Shot Voice Conversion with Pure Transformer Blocks and Triplet Discriminative Training
Sep 03, 2024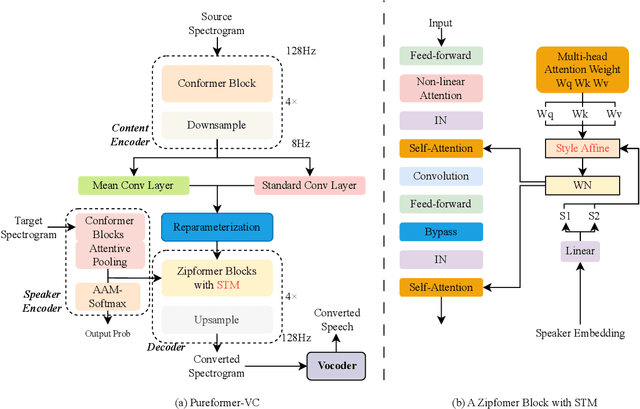
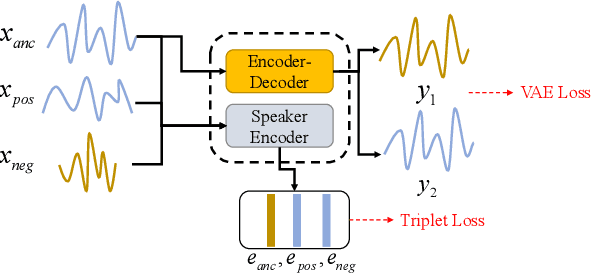


One-shot voice conversion(VC) aims to change the timbre of any source speech to match that of the unseen target speaker with only one speech sample. Existing style transfer-based VC methods relied on speech representation disentanglement and suffered from accurately and independently encoding each speech component and recomposing back to converted speech effectively. To tackle this, we proposed Pureformer-VC, which utilizes Conformer blocks to build a disentangled encoder, and Zipformer blocks to build a style transfer decoder as the generator. In the decoder, we used effective styleformer blocks to integrate speaker characteristics into the generated speech effectively. The models used the generative VAE loss for encoding components and triplet loss for unsupervised discriminative training. We applied the styleformer method to Zipformer's shared weights for style transfer. The experimental results show that the proposed model achieves comparable subjective scores and exhibits improvements in objective metrics compared to existing methods in a one-shot voice conversion scenario.