 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTC-MGC: Text-Conditioned Multi-Grained Contrastive Learning for Text-Video Retrieval
Apr 07, 2025Motivated by the success of coarse-grained or fine-grained contrast in text-video retrieval, there emerge multi-grained contrastive learning methods which focus on the integration of contrasts with different granularity. However, due to the wider semantic range of videos, the text-agnostic video representations might encode misleading information not described in texts, thus impeding the model from capturing precise cross-modal semantic correspondence. To this end, we propose a Text-Conditioned Multi-Grained Contrast framework, dubbed TC-MGC. Specifically, our model employs a language-video attention block to generate aggregated frame and video representations conditioned on the word's and text's attention weights over frames. To filter unnecessary similarity interactions and decrease trainable parameters in the Interactive Similarity Aggregation (ISA) module, we design a Similarity Reorganization (SR) module to identify attentive similarities and reorganize cross-modal similarity vectors and matrices. Next, we argue that the imbalance problem among multigrained similarities may result in over- and under-representation issues. We thereby introduce an auxiliary Similarity Decorrelation Regularization (SDR) loss to facilitate cooperative relationship utilization by similarity variance minimization on matching text-video pairs. Finally, we present a Linear Softmax Aggregation (LSA) module to explicitly encourage the interactions between multiple similarities and promote the usage of multi-grained information. Empirically, TC-MGC achieves competitive results on multiple text-video retrieval benchmarks, outperforming X-CLIP model by +2.8% (+1.3%), +2.2% (+1.0%), +1.5% (+0.9%) relative (absolute) improvements in text-to-video retrieval R@1 on MSR-VTT, DiDeMo and VATEX, respectively. Our code is publicly available at https://github.com/JingXiaolun/TC-MGC.
An Empirical Study of Excitation and Aggregation Design Adaptions in CLIP4Clip for Video-Text Retrieval
May 25, 2024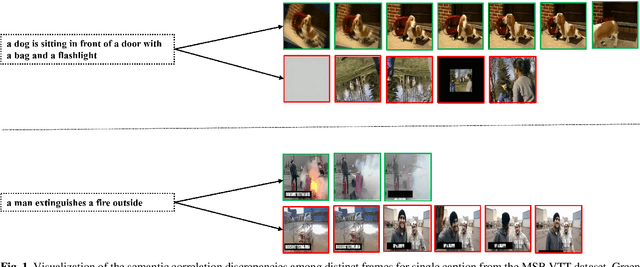
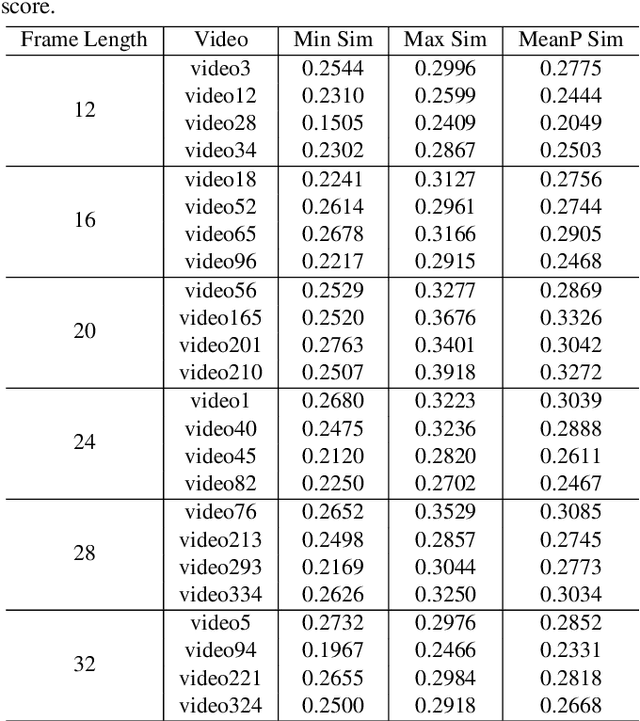
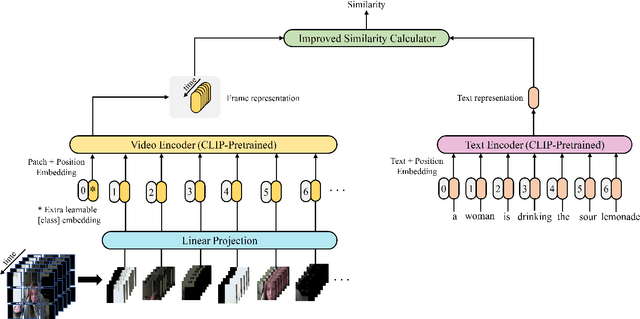
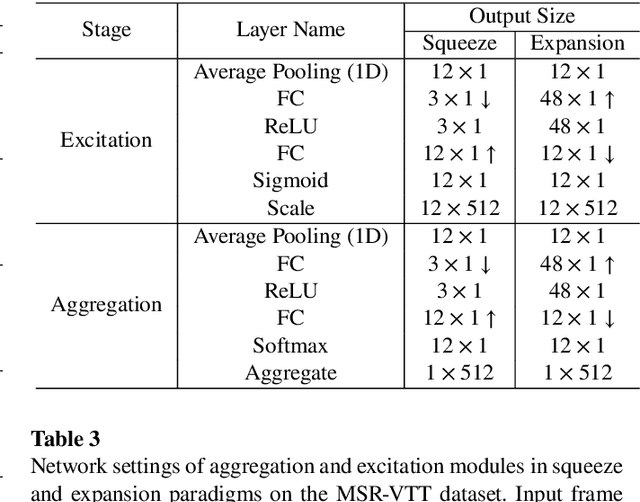
CLIP4Clip model transferred from the CLIP has been the de-factor standard to solve the video clip retrieval task from frame-level input, triggering the surge of CLIP4Clip-based models in the video-text retrieval domain. In this work, we rethink the inherent limitation of widely-used mean pooling operation in the frame features aggregation and investigate the adaptions of excitation and aggregation design for discriminative video representation generation. We present a novel excitationand-aggregation design, including (1) The excitation module is available for capturing non-mutuallyexclusive relationships among frame features and achieving frame-wise features recalibration, and (2) The aggregation module is applied to learn exclusiveness used for frame representations aggregation. Similarly, we employ the cascade of sequential module and aggregation design to generate discriminative video representation in the sequential type. Besides, we adopt the excitation design in the tight type to obtain representative frame features for multi-modal interaction. The proposed modules are evaluated on three benchmark datasets of MSR-VTT, ActivityNet and DiDeMo, achieving MSR-VTT (43.9 R@1), ActivityNet (44.1 R@1) and DiDeMo (31.0 R@1). They outperform the CLIP4Clip results by +1.2% (+0.5%), +4.5% (+1.9%) and +9.5% (+2.7%) relative (absolute) improvements, demonstrating the superiority of our proposed excitation and aggregation designs. We hope our work will serve as an alternative for frame representations aggregation and facilitate future research.