 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Enhancement with Multi-granularity Vector Quantization
Feb 16, 2023With advances in deep learning, neural network based speech enhancement (SE) has developed rapidly in the last decade. Meanwhile, the self-supervised pre-trained model and vector quantization (VQ) have achieved excellent performance on many speech-related tasks, while they are less explored on SE. As it was shown in our previous work that utilizing a VQ module to discretize noisy speech representations is beneficial for speech denoising, in this work we therefore study the impact of using VQ at different layers with different number of codebooks. Different VQ modules indeed enable to extract multiple-granularity speech features. Following an attention mechanism, the contextual features extracted by a pre-trained model are fused with the local features extracted by the encoder, such that both global and local information are preserved to reconstruct the enhanced speech. Experimental results on the Valentini dataset show that the proposed model can improve the SE performance, where the impact of choosing pre-trained models is also revealed.
Speech Enhancement Using Self-Supervised Pre-Trained Model and Vector Quantization
Sep 28, 2022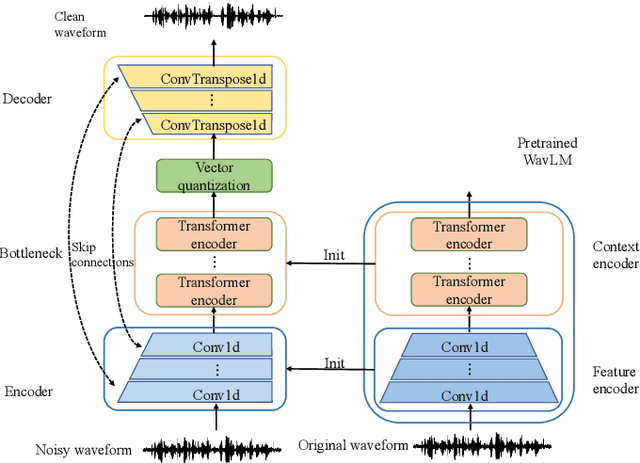



With the development of deep learning, neural network-based speech enhancement (SE) models have shown excellent performance. Meanwhile, it was shown that the development of self-supervised pre-trained models can be applied to various downstream tasks. In this paper, we will consider the application of the pre-trained model to the real-time SE problem. Specifically, the encoder and bottleneck layer of the DEMUCS model are initialized using the self-supervised pretrained WavLM model, the convolution in the encoder is replaced by causal convolution, and the transformer encoder in the bottleneck layer is based on causal attention mask. In addition, as discretizing the noisy speech representations is more beneficial for denoising, we utilize a quantization module to discretize the representation output from the bottleneck layer, which is then fed into the decoder to reconstruct the clean speech waveform. Experimental results on the Valentini dataset and an internal dataset show that the pre-trained model based initialization can improve the SE performance and the discretization operation suppresses the noise component in the representations to some extent, which can further improve the performance.