 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Enhancement Using Self-Supervised Pre-Trained Model and Vector Quantization
Paper and Code
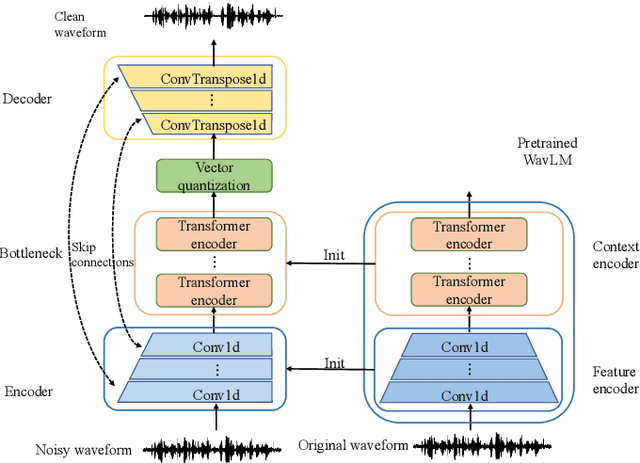



With the development of deep learning, neural network-based speech enhancement (SE) models have shown excellent performance. Meanwhile, it was shown that the development of self-supervised pre-trained models can be applied to various downstream tasks. In this paper, we will consider the application of the pre-trained model to the real-time SE problem. Specifically, the encoder and bottleneck layer of the DEMUCS model are initialized using the self-supervised pretrained WavLM model, the convolution in the encoder is replaced by causal convolution, and the transformer encoder in the bottleneck layer is based on causal attention mask. In addition, as discretizing the noisy speech representations is more beneficial for denoising, we utilize a quantization module to discretize the representation output from the bottleneck layer, which is then fed into the decoder to reconstruct the clean speech waveform. Experimental results on the Valentini dataset and an internal dataset show that the pre-trained model based initialization can improve the SE performance and the discretization operation suppresses the noise component in the representations to some extent, which can further improve the performance.