 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlock Flow: Learning Straight Flow on Data Blocks
Jan 20, 2025Flow-matching models provide a powerful framework for various applications, offering efficient sampling and flexible probability path modeling. These models are characterized by flows with low curvature in learned generative trajectories, which results in reduced truncation error at each sampling step. To further reduce curvature, we propose block matching. This novel approach leverages label information to partition the data distribution into blocks and match them with a prior distribution parameterized using the same label information, thereby learning straighter flows. We demonstrate that the variance of the prior distribution can control the curvature upper bound of forward trajectories in flow-matching models. By designing flexible regularization strategies to adjust this variance, we achieve optimal generation performance, effectively balancing the trade-off between maintaining diversity in generated samples and minimizing numerical solver errors. Our results demonstrate competitive performance with models of the same parameter scale.Code is available at \url{https://github.com/wpp13749/block_flow}.
Training Generative Adversarial Networks with Adaptive Composite Gradient
Nov 10, 2021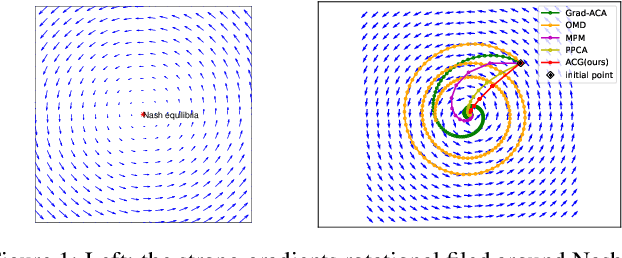
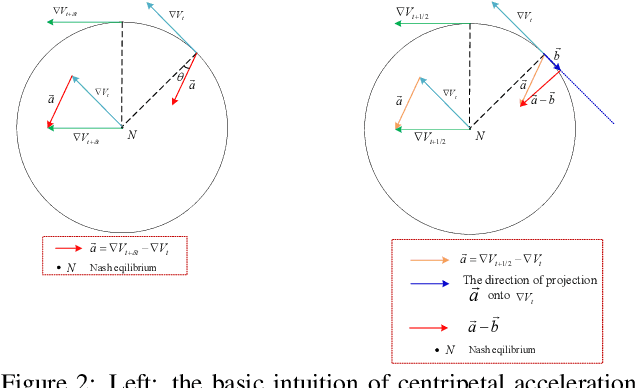
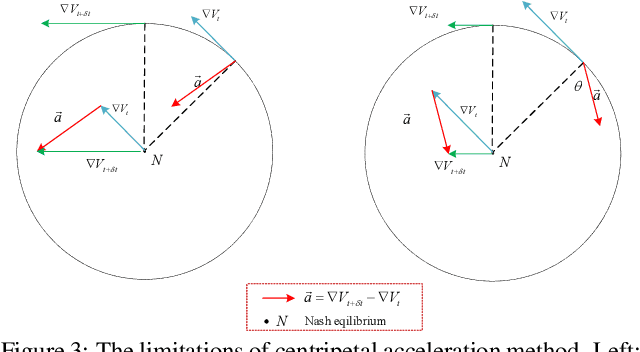
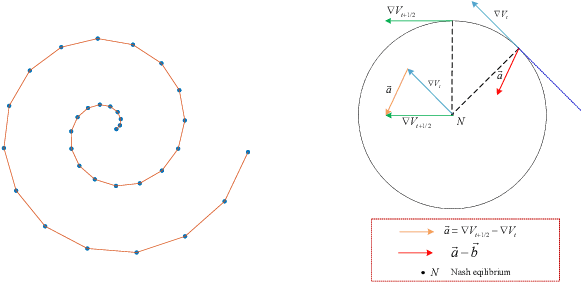
The wide applications of Generative adversarial networks benefit from the successful training methods, guaranteeing that an object function converges to the local minima. Nevertheless, designing an efficient and competitive training method is still a challenging task due to the cyclic behaviors of some gradient-based ways and the expensive computational cost of these methods based on the Hessian matrix. This paper proposed the adaptive Composite Gradients (ACG) method, linearly convergent in bilinear games under suitable settings. Theory and toy-function experiments suggest that our approach can alleviate the cyclic behaviors and converge faster than recently proposed algorithms. Significantly, the ACG method is not only used to find stable fixed points in bilinear games as well as in general games. The ACG method is a novel semi-gradient-free algorithm since it does not need to calculate the gradient of each step, reducing the computational cost of gradient and Hessian by utilizing the predictive information in future iterations. We conducted two mixture of Gaussians experiments by integrating ACG to existing algorithms with Linear GANs. Results show ACG is competitive with the previous algorithms. Realistic experiments on four prevalent data sets (MNIST, Fashion-MNIST, CIFAR-10, and CelebA) with DCGANs show that our ACG method outperforms several baselines, which illustrates the superiority and efficacy of our method.