 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Sampling for Storage of Progressive Images on DNA
Mar 05, 2026The short lifespan of traditional data storage media, coupled with an exponential increase in storage demand, has made long-term archival a fundamental problem in the data storage industry and beyond. Consequently, researchers are looking for innovative media solutions that can store data over long time periods at a very low cost. DNA molecules, with their high density, long lifespan, and low energy needs, have emerged as a viable alternative to digital data archival. However, current DNA data storage technologies are facing challenges with respect to cost and reliability. Thus, coding rate and error robustness are critical to scale DNA storage and make it technologically and economically achievable. Moreover, the molecules of DNA that encode different files are often located in the same oligo pool. Without random access solutions at the oligo level, it is very impractical to decode a specific file from these mixed pools, as all oligos need to first be sequenced and decoded before a target file can be retrieved, which greatly deteriorates the read cost. This paper introduces a solution to efficiently encode and store images into DNA molecules, that aims at reducing the read cost necessary to retrieve a resolution-reduced version of an image. This image storage system is based on the Progressive Decoding Functionality of the JPEG2000 codec but can be adapted to any conventional progressive codec. Each resolution layer is encoded into a set of oligos using the JPEG DNA VM codec, a DNA-based coder that aims at retrieving a file with a high reliability. Depending on the desired resolution to be read, the set of oligos as well as the portion of the oligos to be sequenced and decoded are adjusted accordingly. These oligos will be selected at sequencing time, with the help of the adaptive sampling method provided by the Nanopore sequencers, making it a PCR-free random access solution.
Combining Progressive Image Compression and Random Access in DNA Data Storage
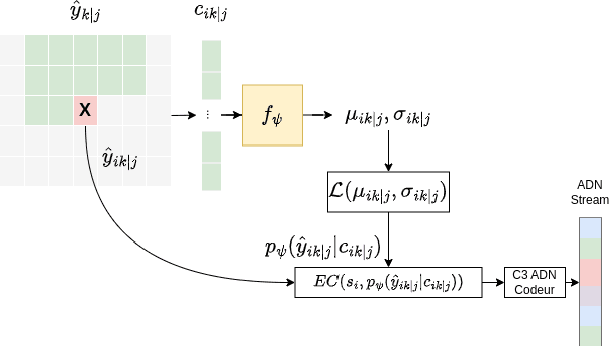
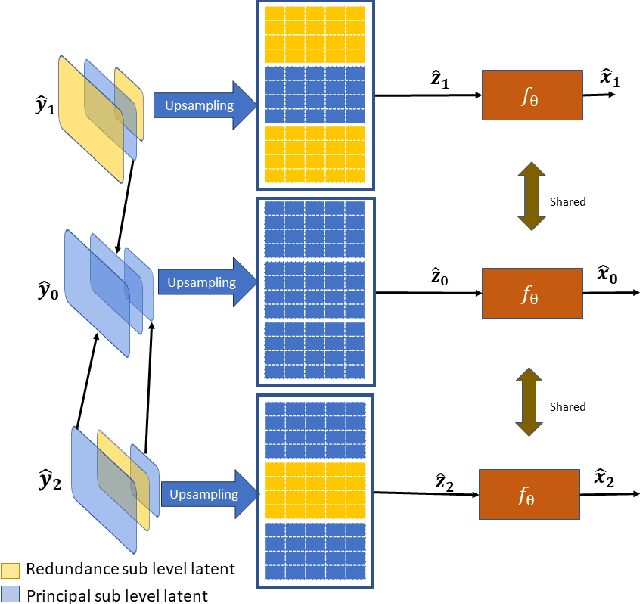
May 21, 2025The exponential increase in storage demand and low lifespan of data storage devices has resulted in long-term archival and preservation emerging as a critical bottlenecks in data storage. In order to meet this demand, researchers are now investigating novel forms of data storage media. The high density, long lifespan and low energy needs of synthetic DNA make it a promising candidate for long-term data archival. However, current DNA data storage technologies are facing challenges with respect to cost (writing data to DNA is expensive) and reliability (reading and writing data is error prone). Thus, data compression and error correction are crucial to scale DNA storage. Additionally, the DNA molecules encoding several files are very often stored in the same place, called an oligo pool. For this reason, without random access solutions, it is relatively impractical to decode a specific file from the pool, because all the oligos from all the files need to first be sequenced, which greatly deteriorates the read cost. This paper introduces PIC-DNA - a novel JPEG2000-based progressive image coder adapted to DNA data storage. This coder directly includes a random access process in its coding system, allowing for the retrieval of a specific image from a pool of oligos encoding several images. The progressive decoder can dynamically adapt the read cost according to the user's cost and quality constraints at decoding time. Both the random access and progressive decoding greatly improve on the read-cost of image coders adapted to DNA.
Implicit Neural Multiple Description for DNA-based data storage
Sep 13, 2023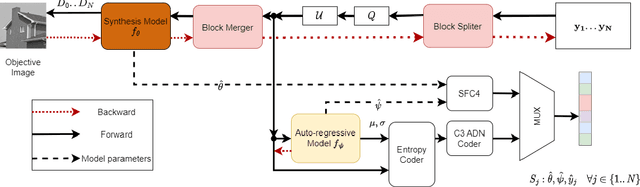


DNA exhibits remarkable potential as a data storage solution due to its impressive storage density and long-term stability, stemming from its inherent biomolecular structure. However, developing this novel medium comes with its own set of challenges, particularly in addressing errors arising from storage and biological manipulations. These challenges are further conditioned by the structural constraints of DNA sequences and cost considerations. In response to these limitations, we have pioneered a novel compression scheme and a cutting-edge Multiple Description Coding (MDC) technique utilizing neural networks for DNA data storage. Our MDC method introduces an innovative approach to encoding data into DNA, specifically designed to withstand errors effectively. Notably, our new compression scheme overperforms classic image compression methods for DNA-data storage. Furthermore, our approach exhibits superiority over conventional MDC methods reliant on auto-encoders. Its distinctive strengths lie in its ability to bypass the need for extensive model training and its enhanced adaptability for fine-tuning redundancy levels. Experimental results demonstrate that our solution competes favorably with the latest DNA data storage methods in the field, offering superior compression rates and robust noise resilience.
INR-MDSQC: Implicit Neural Representation Multiple Description Scalar Quantization for robust image Coding
Jun 24, 2023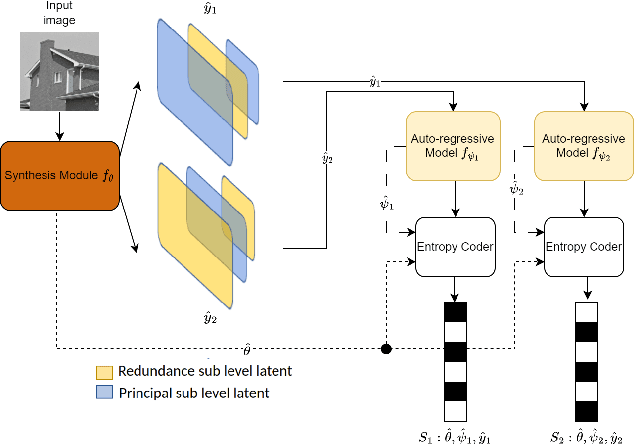
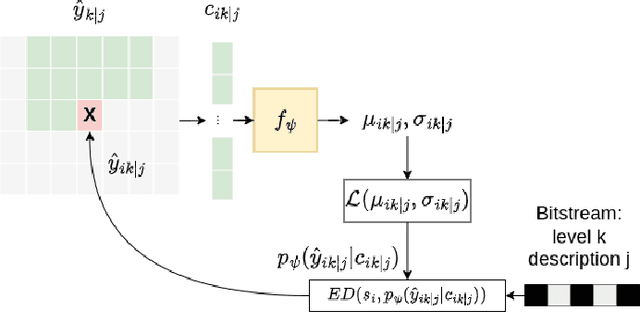
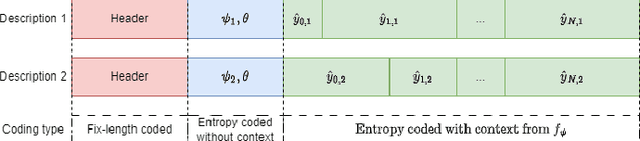
Multiple Description Coding (MDC) is an error-resilient source coding method designed for transmission over noisy channels. We present a novel MDC scheme employing a neural network based on implicit neural representation. This involves overfitting the neural representation for images. Each description is transmitted along with model parameters and its respective latent spaces. Our method has advantages over traditional MDC that utilizes auto-encoders, such as eliminating the need for model training and offering high flexibility in redundancy adjustment. Experiments demonstrate that our solution is competitive with autoencoder-based MDC and classic MDC based on HEVC, delivering superior visual quality.
MQ-Coder inspired arithmetic coder for synthetic DNA data storage
Jun 22, 2023



Over the past years, the ever-growing trend on data storage demand, more specifically for "cold" data (i.e. rarely accessed), has motivated research for alternative systems of data storage. Because of its biochemical characteristics, synthetic DNA molecules are now considered as serious candidates for this new kind of storage. This paper introduces a novel arithmetic coder for DNA data storage, and presents some results on a lossy JPEG 2000 based image compression method adapted for DNA data storage that uses this novel coder. The DNA coding algorithms presented here have been designed to efficiently compress images, encode them into a quaternary code, and finally store them into synthetic DNA molecules. This work also aims at making the compression models better fit the problematic that we encounter when storing data into DNA, namely the fact that the DNA writing, storing and reading methods are error prone processes. The main take away of this work is our arithmetic coder and it's integration into a performant image codec.
Image storage on synthetic DNA using compressive autoencoders and DNA-adapted entropy coders
Jun 22, 2023



Over the past years, the ever-growing trend on data storage demand, more specifically for "cold" data (rarely accessed data), has motivated research for alternative systems of data storage. Because of its biochemical characteristics, synthetic DNA molecules are now considered as serious candidates for this new kind of storage. This paper presents some results on lossy image compression methods based on convolutional autoencoders adapted to DNA data storage, with synthetic DNA-adapted entropic and fixed-length codes. The model architectures presented here have been designed to efficiently compress images, encode them into a quaternary code, and finally store them into synthetic DNA molecules. This work also aims at making the compression models better fit the problematics that we encounter when storing data into DNA, namely the fact that the DNA writing, storing and reading methods are error prone processes. The main take aways of this kind of compressive autoencoder are our latent space quantization and the different DNA adapted entropy coders used to encode the quantized latent space, which are an improvement over the fixed length DNA adapted coders that were previously used.
* arXiv admin note: substantial text overlap with arXiv:2203.09981
Rotating labeling of entropy coders for synthetic DNA data storage
Apr 02, 2023Over the past years, the ever-growing trend on data storage demand, more specifically for "cold" data (i.e. rarely accessed), has motivated research for alternative systems of data storage. Because of its biochemical characteristics, synthetic DNA molecules are considered as potential candidates for a new storage paradigm. Because of this trend, several coding solutions have been proposed over the past years for the storage of digital information into DNA. Despite being a promising solution, DNA storage faces two major obstacles: the large cost of synthesis and the noise introduced during sequencing. Additionally, this noise increases when biochemically defined coding constraints are not respected: avoiding homopolymers and patterns, as well as balancing the GC content. This paper describes a novel entropy coder which can be embedded to any block-based image-coding schema and aims to robustify the decoded results. Our proposed solution introduces variability in the generated quaternary streams, reduces the amount of homopolymers and repeated patterns to reduce the probability of errors occurring. In this paper, we integrate the proposed entropy coder into four existing JPEG-inspired DNA coders. We then evaluate the quality -- in terms of biochemical constraints -- of the encoded data for all the different methods.
A constrained Shannon-Fano entropy coder for image storage in synthetic DNA
Mar 18, 2022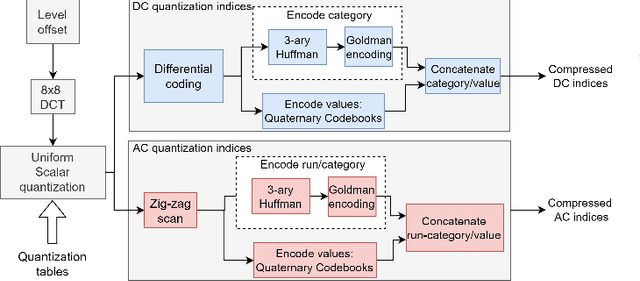
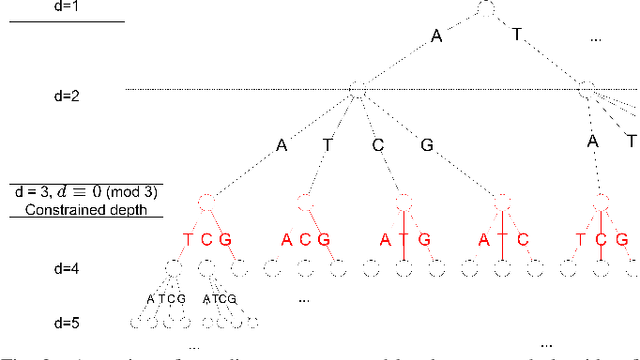
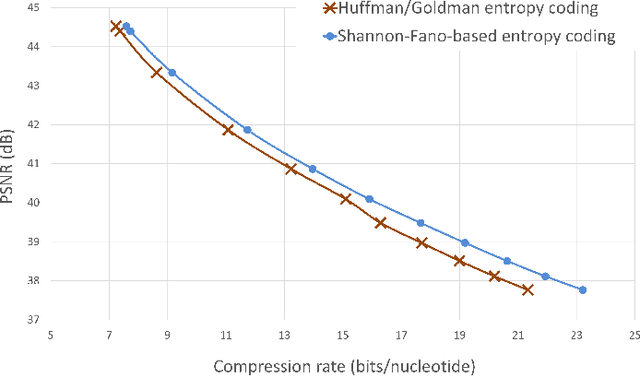
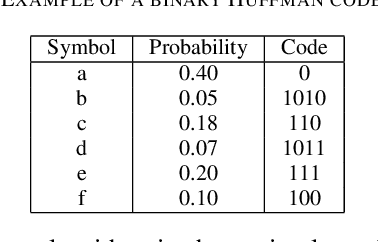
The exponentially increasing demand for data storage has been facing more and more challenges during the past years. The energy costs that it represents are also increasing, and the availability of the storage hardware is not able to follow the storage demand's trend. The short lifespan of conventional storage media -- 10 to 20 years - forces the duplication of the hardware and worsens the situation. The majority of this storage demand concerns "cold" data, data very rarely accessed but that has to be kept for long periods of time. The coding abilities of synthetic DNA, and its long durability (several hundred years), make it a serious candidate as an alternative storage media for "cold" data. In this paper, we propose a variable-length coding algorithm adapted to DNA data storage with improved performance. The proposed algorithm is based on a modified Shannon-Fano code that respects some biochemichal constraints imposed by the synthesis chemistry. We have inserted this code in a JPEG compression algorithm adapted to DNA image storage and we highlighted an improvement of the compression ratio ranging from 0.5 up to 2 bits per nucleotide compared to the state-of-the-art solution, without affecting the reconstruction quality.
Image Storage on Synthetic DNA Using Autoencoders
Mar 18, 2022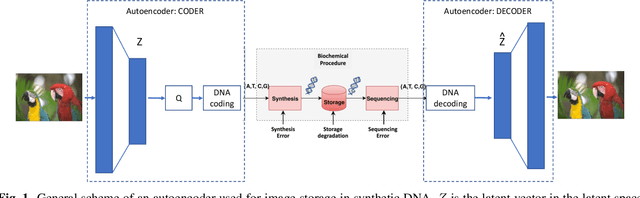


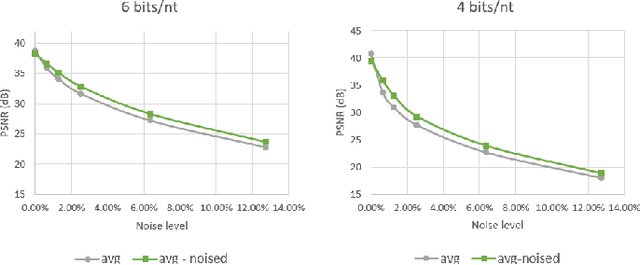
Over the past years, the ever-growing trend on data storage demand, more specifically for "cold" data (rarely accessed data), has motivated research for alternative systems of data storage. Because of its biochemical characteristics, synthetic DNA molecules are now considered as serious candidates for this new kind of storage. This paper presents some results on lossy image compression methods based on convolutional autoencoders adapted to DNA data storage. The model architectures presented here have been designed to efficiently compress images, encode them into a quaternary code, and finally store them into synthetic DNA molecules. This work also aims at making the compression models better fit the problematics that we encounter when storing data into DNA, namely the fact that the DNA writing, storing and reading methods are error prone processes. The main take away of this kind of compressive autoencoder is our quantization and the robustness to substitution errors thanks to the noise model that we use during training.