 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing a composite model versus chained models to locate a nearest visual object
Jun 02, 2023



Extracting information from geographic images and text is crucial for autonomous vehicles to determine in advance the best cell stations to connect to along their future path. Multiple artificial neural network models can address this challenge; however, there is no definitive guidance on the selection of an appropriate model for such use cases. Therefore, we experimented two architectures to solve such a task: a first architecture with chained models where each model in the chain addresses a sub-task of the task; and a second architecture with a single model that addresses the whole task. Our results showed that these two architectures achieved the same level performance with a root mean square error (RMSE) of 0.055 and 0.056; The findings further revealed that when the task can be decomposed into sub-tasks, the chain architecture exhibits a twelve-fold increase in training speed compared to the composite model. Nevertheless, the composite model significantly alleviates the burden of data labeling.
Tackling Asymmetric and Circular Sequential Social Dilemmas with Reinforcement Learning and Graph-based Tit-for-Tat
Jun 26, 2022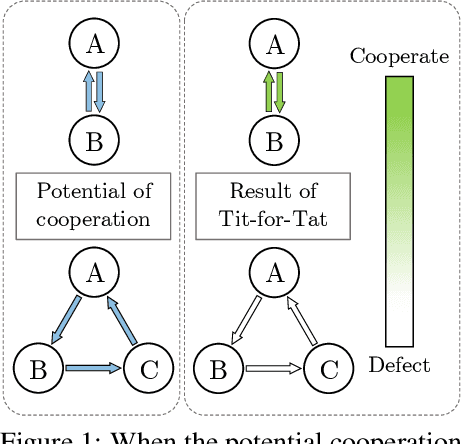


In many societal and industrial interactions, participants generally prefer their pure self-interest at the expense of the global welfare. Known as social dilemmas, this category of non-cooperative games offers situations where multiple actors should all cooperate to achieve the best outcome but greed and fear lead to a worst self-interested issue. Recently, the emergence of Deep Reinforcement Learning (RL) has generated revived interest in social dilemmas with the introduction of Sequential Social Dilemma (SSD). Cooperative agents mixing RL policies and Tit-for-tat (TFT) strategies have successfully addressed some non-optimal Nash equilibrium issues. However, this kind of paradigm requires symmetrical and direct cooperation between actors, conditions that are not met when mutual cooperation become asymmetric and is possible only with at least a third actor in a circular way. To tackle this issue, this paper extends SSD with Circular Sequential Social Dilemma (CSSD), a new kind of Markov games that better generalizes the diversity of cooperation between agents. Secondly, to address such circular and asymmetric cooperation, we propose a candidate solution based on RL policies and a graph-based TFT. We conducted some experiments on a simple multi-player grid world which offers adaptable cooperation structures. Our work confirmed that our graph-based approach is beneficial to address circular situations by encouraging self-interested agents to reach mutual cooperation.
GIPFA: Generating IPA Pronunciation from Audio
Jun 13, 2020

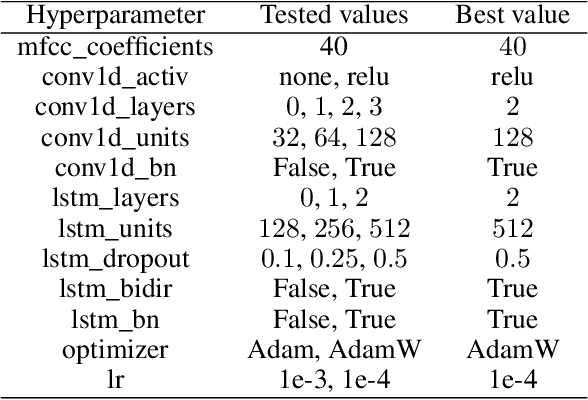
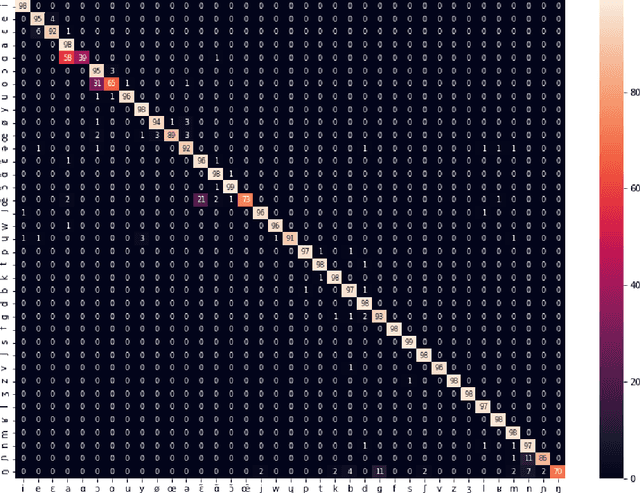
Transcribing spoken audio samples into International Phonetic Alphabet (IPA) has long been reserved for experts. In this study, we instead examined the use of an Artificial Neural Network (ANN) model to automatically extract the IPA pronunciation of a word based on its audio pronunciation, hence its name Generating IPA Pronunciation From Audio (GIPFA). Based on the French Wikimedia dictionary, we trained our model which then correctly predicted 75% of the IPA pronunciations tested. Interestingly, by studying inference errors, the model made it possible to highlight possible errors in the dataset as well as identifying the closest phonemes in French.
OTEANN: Estimating the Transparency of Orthographies with an Artificial Neural Network
Dec 31, 2019
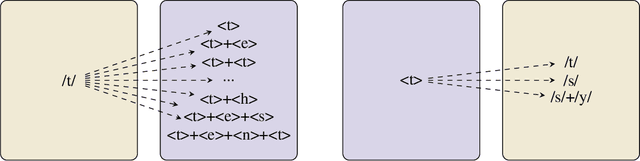

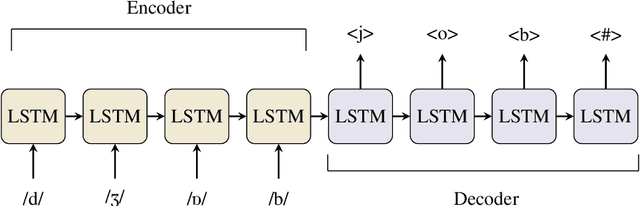
To transcribe spoken language to written medium, most alphabets enable an unambiguous sound-to-letter rule. However, some writing systems have distanced themselves from this simple concept and little work exists on measuring such distance. In this study, we use an Artificial Neural Network (ANN) model to evaluate the transparency between written words and their pronunciation, hence its name Orthographic Transparency Estimation with an ANN (OTEANN). Based on datasets derived from Wikimedia dictionaries, we trained and tested this model to score the percentage of false predictions in phoneme-to-grapheme and grapheme-to-phoneme translation tasks. The scores obtained on 15 orthographies were in line with the estimations of other studies. Interestingly, the model also provided insight into typical mistakes made by learners who only consider the phonemic rule in reading and writing.